Éliminer la récursion gauche. Analyse Supprimer la récursion gauche en ligne
Classification des grammaires formelles selon Chomsky
· Grammaire de type 0 (forme générale). Les règles ont la forme α→β
· Grammaire type 1 (dépendant du contexte, KZ)
Les règles ont la forme αAβ → αγβ. γ appartient à V +, c'est-à-dire la grammaire n'est pas tronquée
α,β sont appelés contexte gauche et droite
· Grammaire type 2 (sans contexte, KS)
Les règles sont de la forme A → α. α appartient à V*, c'est-à-dire la grammaire peut être raccourcie => les langues KS ne sont pas contenues dans KS
Le plus proche du BPF
· Grammaire type 3 (automatique, régulière)
Les règles sont de la forme A → aB, A → a, A → ε
Les langages automatiques sont contenus dans les langages KS
Exemple. Une grammaire qui génère un langage d'expressions régulières entre parenthèses.
S → (S) | SS | ε
Génération (inférence)
Désignations
=>+ (1 ou plus)
=>* (0 ou plus)
Forme phrasenelle de la grammaire est une chaîne qui peut être dérivée du caractère de début.
Phrase (sentiment) de grammaire est une forme phrase composée uniquement de terminaux.
Grammaire du langage L(G)- c'est l'ensemble de toutes ses propositions.
Désignations :
Sortie gauche, droite (génération).
Sortie gauche et droite pour la phrase i + i * i
L'arbre de sortie (arbre syntaxique, arbre d'analyse) d'une chaîne de phrase. Contrairement à la génération, les informations sur l’ordre d’inférence en sont exclues.
Analyser la couronne de l'arbre - chaîne de marques de feuilles de gauche à droite
Une grammaire qui produit plus d'un arbre d'analyse pour une phrase est appelée ambiguë.
Un exemple de grammaire ambiguë. Grammaire des expressions arithmétiques.
E → E+E | E*E | je
Deux arbres d'analyse pour la chaîne i + i * i
Un exemple de grammaire ambiguë. Grammaire des instructions conditionnelles
S → si b alors S
| si b alors S sinon S
Deux arbres d'analyse pour la chaîne si b alors si b alors a
Convertir en grammaire équivalente sans ambiguïté :
S → si b alors S
| si b alors S2 sinon S
S2 → si b alors S2 sinon S2
44. Langages formels et grammaires : langages non vides, finis et infinis

45.Équivalence et minimisation des automates
Équivalence des machines à états finis
Soit S un alphabet (un ensemble fini de symboles) et S* l'ensemble de tous les mots de l'alphabet S. Notons e un mot vide, c'est-à-dire ne contient pas du tout de lettres (symboles de S), mais le signe × - l'opération d'attribution (concaténation) de mots.
Donc, aav × va = aavva. Le signe × de l’opération d’attribution est souvent omis.
Les mots de l'alphabet S seront désignés par de petites lettres grecques a, b, g, .... Evidemment, e est l'unité de l'opération d'attribution :
Il est également évident que l'opération d'attribution est associative, c'est-à-dire (ab)g = une(bg).
Ainsi, l'ensemble S* de tous les mots de l'alphabet S par rapport à l'opération d'affectation est un semi-groupe avec identité, c'est-à-dire monoïde;
S* est appelé monoïde libre sur l’alphabet S.
Minimisation de la machine à états
Différentes machines à états peuvent fonctionner de manière identique, même si elles ont numéro différentÉtats. Une tâche importante consiste à trouver une machine à états finis minimale qui implémente un mappage d’automate donné.
Il est naturel d’appeler équivalents deux états d’un automate, qui ne peuvent être distingués par aucun mot d’entrée.
Définition 1 : Deux états p et q d'une machine à états finis
A = (S,X,Y,s0,d,l) sont appelés équivalents (notés p~q) si ("aО X*)l*(p,a) =l*(q, a)
46. Équivalence des machines de Turing mono-bande et multi-bande
Il est évident que le concept de k-tape MT est plus large que le concept de machine à bande unique « normale ». DÉFINITION 6. (k+1)-machine à bande M′ avec le programme w simule la machine à k-bande M si pour tout ensemble de mots d'entrée (x1, x2, …, xk) le résultat du travail M′ coïncide avec le résultat du travail M sur les mêmes données d'entrée. On suppose que le mot w est écrit en premier sur la (k+1)ième bande M'. Le résultat s'entend comme l'état des k premières bandes MT au moment de l'arrêt, et si M ne s'arrête pas à une entrée donnée, alors la machine qui le simule ne doit pas non plus s'arrêter à cette entrée.
DÉFINITION 7. Une (k+1)-bande MT M* est appelée une machine de Turing universelle pour les machines à k-tape si pour toute machine à k-tape M il existe un programme w sur lequel M* simule M. 12 Veuillez noter : dans la définition d'un MT universel, la même machine M′ doit simuler différentes machines à k-tape (sur différents programmes w). Considérons le théorème suivant. THÉORÈME 3. Pour tout k≥1, il existe un magnétophone universel (k+1)–Turing. Preuve. Prouvons le théorème de manière constructive, c'est-à-dire nous allons montrer comment vous pouvez construire le requis voiture universelle M*. Considérons uniquement le schéma général de construction, en omettant les détails complexes. L'idée principale est de placer une description de la machine de Turing simulée sur une (k+1)-ème bande supplémentaire et d'utiliser cette description pendant le processus de simulation.
DÉFINITION 8. Nous dirons que la machine de Turing M calcule fonction partielle f:A*→A*, si pour tout x∈A* écrit sur la première bande de la machine M : si f(x) est défini, alors M s'arrête, et au moment de l'arrêt le mot f(x) est écrit sur la dernière bande de la machine ; si f(x) n'est pas défini, alors la machine M ne s'arrête pas.
DÉFINITION 9. On dira que les machines M et M′ sont équivalentes si elles calculent la même fonction. La notion d'équivalence est « plus faible » que la simulation : si une machine M' simule une machine M, alors la machine M' est équivalente à M ; l’inverse, d’une manière générale, n’est pas vrai. En revanche, la simulation nécessite que M′ ait au moins autant de bandes que M, alors que l’équivalence n’en nécessite pas 15. C'est cette propriété qui permet de formuler et de prouver le théorème suivant.
THÉORÈME 4. Pour toute machine à k-bandes M de complexité temporelle T(n), il existe une machine à une bande équivalente M′ de complexité temporelle T′ (n) = O(T 2 (n)).
48. Transformations équivalentes des grammaires KS : exclusion des règles de chaîne, suppression d'une règle de grammaire arbitraire
Définition. Règle de grammaire gentille , Où , V A s'appelle chaîne.
Déclaration. Pour une grammaire KS Γ contenant des règles de chaîne, il est possible de construire une grammaire équivalente Γ" qui ne contient pas de règles de chaîne.
L'idée de la preuve est la suivante. Si le schéma grammatical a la forme
R = (..., ,...,
alors une telle grammaire équivaut à une grammaire avec un schéma
R" = (..., un
puisque la sortie dans la grammaire avec le schéma R de la chaîne a
peut être obtenu dans une grammaire avec le schéma R" en utilisant la règle un
En général, la preuve de la dernière affirmation peut être effectuée comme suit. Découpons R en deux sous-ensembles R 1 et R 2, incluant dans R 1 toutes les règles de la forme
Pour chaque règle de R 1 nous trouvons un ensemble de règles S( ), qui sont construits comme ceci :
Si *et dans R 2 il y a une règle α, où α est la chaîne du dictionnaire (V t V A)*, alors dans S( ) activer la règle
Construisons nouveau schéma R" en combinant les règles R 2 et tous les ensembles construits S( ). On obtient une grammaire Г" = (V t, V A , I, R"), qui est équivalente à celle donnée et ne contient pas de règles de la forme .
A titre d'exemple, effectuons l'exception des règles de chaîne de la grammaire de G 1.9 avec le schéma :
R=(
Tout d’abord, divisons les règles de grammaire en deux sous-ensembles :
R 1 = (
R2 = (
Pour chaque règle de R 1 nous construisons un sous-ensemble correspondant.
S(
S(
En conséquence, nous obtenons le schéma de grammaire souhaité sans règles de chaîne sous la forme :
R2US(
Le dernier type de transformation considéré est associé à la suppression des règles avec un côté droit vide de la grammaire.
Définition. Règle aimable $ est appelé règle d'annulation.
49.Transformations équivalentes des grammaires KS : suppression des symboles inutiles.
Soit une grammaire KS arbitraire g . Non terminal UN cette grammaire s'appelle productif , s'il existe une chaîne de terminaux (y compris vide) telle que UN Þ * un improductif.
Théorème. Chaque grammaire CS est équivalente à une grammaire CS sans non-terminaux improductifs.
Non terminal UN grammaire g appelé réalisable , si une telle chaîne existe un , Quoi S Þ * un . Sinon, le non-terminal est appelé inaccessible.
Théorème. Chaque grammaire KS est équivalente à une grammaire KS sans non-terminaux inaccessibles.
Un symbole non terminal dans une grammaire KS est appelé inutile (ou redondant) , si cela est soit inaccessible, soit improductif.
Théorème. Chaque grammaire CS est équivalente à une grammaire CS dans laquelle il n'y a pas de non-terminaux inutiles.
Exemple.Éliminez les symboles inutiles dans la grammaire
S® CA | UN; UN ® taxi; B ® b ; C ® un.
Étape 1. Nous construisons beaucoup réalisable personnages: {S} ® { S, C, A}® { S, C, A, B}. Tous les non-terminaux sont accessibles. Il n’y en a pas d’inaccessibles, la grammaire ne change pas.
Étape 2. Nous construisons beaucoup productif personnages: {C, B}® { S, C, B}. Nous obtenons cela UN - pas productif. Nous le jetons ainsi que toutes les règles qui l'accompagnent hors de la grammaire. On a
S® CA ; B ® b ; C ® un.
Étape 3. Nous construisons beaucoup réalisable symboles de la nouvelle grammaire : {S} ® { S, C}. Nous obtenons cela B inaccessible. Nous le jetons ainsi que toutes les règles qui l'accompagnent hors de la grammaire. On a
S® CA ; C ® un.
C'est le résultat final.
50. Transformations équivalentes des grammaires KS : élimination de la récursion gauche, factorisation gauche
Supprimer la récursion gauche
La principale difficulté lors de l’utilisation de l’analyse prédictive est de trouver une grammaire pour le langage d’entrée qui peut être utilisée pour créer un tableau d’analyse avec des entrées définies de manière unique. Parfois, avec quelques transformations simples, une grammaire non-LL(1) peut être réduite à une grammaire LL(1) équivalente. Parmi ces transformations, les plus efficaces sont la factorisation à gauche et la suppression. récursion gauche. Deux points doivent être soulignés ici. Premièrement, toutes les grammaires ne deviennent pas LL(1) après ces transformations, et deuxièmement, après de telles transformations, la grammaire résultante peut devenir moins compréhensible.
La récursivité directe vers la gauche, c'est-à-dire la récursivité du formulaire, peut être supprimée de la manière suivante. Nous regroupons d’abord les règles A :
où aucune des chaînes ne commence par A. Ensuite, nous remplaçons cet ensemble de règles par
![]()
où A" est un nouveau non-terminal. À partir du non-terminal A, vous pouvez dériver les mêmes chaînes qu'avant, mais maintenant vous ne pouvez plus récursion gauche. Cette procédure supprime tous les récursions gauches, mais la récursion gauche impliquant deux étapes ou plus n'est pas supprimée. Donnée ci-après algorithme 4.8 permet de tout supprimer récursions gauches de la grammaire.
Factorisation à gauche
L'idée principale de la factorisation à gauche est que dans le cas où il n'est pas clair laquelle des deux alternatives doit être utilisée pour développer un non-terminal A, il faut modifier les règles A afin de reporter la décision jusqu'à ce qu'il y ait suffisamment d'informations pour prendre la bonne décision.
Si ![]() - deux règles A et la chaîne d'entrée commence par une chaîne non vide, dont on ne sait pas s'il faut développer selon la première règle ou la seconde. Vous pouvez différer la décision en développant . Ensuite, après avoir analysé ce qui est déductible, vous pouvez développer par ou par . Les règles factorisées à gauche prennent la forme
- deux règles A et la chaîne d'entrée commence par une chaîne non vide, dont on ne sait pas s'il faut développer selon la première règle ou la seconde. Vous pouvez différer la décision en développant . Ensuite, après avoir analysé ce qui est déductible, vous pouvez développer par ou par . Les règles factorisées à gauche prennent la forme
![]()
51. Langage machine de Turing.
La machine de Turing comprend un nombre illimité dans les deux sens ruban(Il est possible que des machines de Turing aient plusieurs bandes infinies), divisées en cellules et dispositif de contrôle(aussi appelé tête de lecture-écriture (GZCH)), capable d'être dans l'un des ensemble d'états. Le nombre d'états possibles du dispositif de commande est fini et précisément précisé.
Le dispositif de contrôle peut se déplacer à gauche et à droite le long de la bande, lire et écrire des caractères d'un alphabet fini dans des cellules. Se démarque particulièrement vide un symbole qui remplit toutes les cellules de la bande, à l'exception de celles d'entre elles (le numéro final) sur lesquelles les données d'entrée sont écrites.
Le dispositif de commande fonctionne selon règles de transition, qui représentent l'algorithme, réalisable cette machine de Turing. Chaque règle de transition demande à la machine, en fonction de l'état actuel et du symbole observé dans la cellule actuelle, d'écrire dans cette cellule nouveau symbole, passez à un nouvel état et déplacez une cellule vers la gauche ou la droite. Certains états de la machine de Turing peuvent être étiquetés comme suit : Terminal, et accéder à l'un d'entre eux signifie la fin du travail, l'arrêt de l'algorithme.
Une machine de Turing s'appelle déterministe, si chaque combinaison d'état et de symbole de ruban dans le tableau correspond à au plus une règle. S'il existe une paire "symbole du ruban - état" pour laquelle il y a 2 instructions ou plus, une telle machine de Turing est appelée non déterministe.
LL(k)-grammaire si, pour une chaîne donnée et les k premiers caractères (le cas échéant) résultant de , il existe au plus une règle qui peut être appliquée à A pour obtenir la sortie d'une chaîne terminale,
Riz. 4.4.
en commençant et en continuant avec les k bornes mentionnées.
Une grammaire est appelée grammaire LL(k) si elle est une grammaire LL(k) pour certains k.
Exemple 4.7. Considérez la grammaire G = ((S, A, B), (0, 1, a, b), P, S), où P est constitué de règles
S -> A | B, A -> aAb | 0, B -> aBbb | 1.
Ici . G n'est pas une grammaire LL (k) pour tout k. Intuitivement, si nous commençons par lire une chaîne de caractères suffisamment longue a , nous ne savons pas laquelle des règles S -> A et S -> B a été appliquée en premier jusqu'à ce que nous rencontrions 0 ou 1 .
Adressage définition précise LL (k)-grammaires, put et y = a k 1b 2k . Puis conclusions

correspondent aux conclusions (1) et (2) de la définition. Les k premiers caractères des chaînes x et y sont identiques. Cependant, la conclusion est fausse. Puisque k est choisi ici arbitrairement, G n’est pas une grammaire LL.
Conséquences de la définition de la grammaire LL(k)
Théorème 4.6. Grammaire KS est une grammaire LL(k) si et seulement si pour deux règles différentes et du carrefour P vide avec tout ça , Quoi ![]() .
.
Preuve. Nécessité. Supposons cela et satisfaisons aux conditions du théorème, et contient x . Alors, par la définition de FIRST, pour certains y et z il y a des conclusions

(Notez qu'ici nous avons profité du fait que N ne contient pas de non-terminaux inutiles, comme cela est supposé pour toutes les grammaires considérées.) Si |x|< k ; то y = z = e . Так как , то G не LL (k)- грамматика .
Adéquation. Supposons que G n’est pas une grammaire LL(k).
Il y a alors deux conclusions
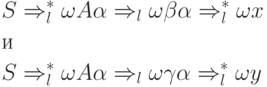
que les chaînes x et y coïncident dans les k premières positions, mais . C'est pourquoi - règles différentes de P et chacun des ensembles ![]() Et
Et ![]() contient la chaîne PREMIER k (x) coïncidant avec la chaîne PREMIER k (y).
contient la chaîne PREMIER k (x) coïncidant avec la chaîne PREMIER k (y).
Exemple 4.8. Une grammaire G composée de deux règles S -> aS | a ne sera pas une grammaire LL(1), puisque
PREMIER 1 (aS) = PREMIER 1 (a) = a.
Intuitivement, cela peut s'expliquer ainsi : en voyant uniquement ce premier caractère lors de l'analyse d'une chaîne commençant par le symbole a, on ne sait pas laquelle des règles S -> aS ou S -> a doit être appliquée à S. D’un autre côté, G est une grammaire LL(2). En effet, dans la notation du théorème qui vient d'être présenté, si ![]() , alors A = S et . Puisque seules les deux règles indiquées sont données pour S, alors . Puisque FIRST2(aS) = aa et FIRST2(a) = a, alors d'après le dernier théorème G sera une LL (2)-grammaire.
, alors A = S et . Puisque seules les deux règles indiquées sont données pour S, alors . Puisque FIRST2(aS) = aa et FIRST2(a) = a, alors d'après le dernier théorème G sera une LL (2)-grammaire.
Supprimer la récursion gauche
La principale difficulté lors de l’utilisation de l’analyse prédictive est de trouver une grammaire pour le langage d’entrée qui peut être utilisée pour créer un tableau d’analyse avec des entrées définies de manière unique. Parfois, avec quelques transformations simples, une grammaire non-LL(1) peut être réduite à une grammaire LL(1) équivalente. Parmi ces transformations, les plus efficaces sont la factorisation à gauche et la suppression de la récursion à gauche. Deux points doivent être soulignés ici. Premièrement, toutes les grammaires ne deviennent pas LL(1) après ces transformations, et deuxièmement, après de telles transformations, la grammaire résultante peut devenir moins compréhensible.
La récursivité directe vers la gauche, c'est-à-dire la récursivité du formulaire, peut être supprimée de la manière suivante. Nous regroupons d’abord les règles A :
où aucune des lignes ne commence par A . Ensuite, nous remplaçons cet ensemble de règles par
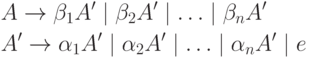
où A" est le nouveau non-terminal. Les mêmes chaînes peuvent être déduites du non-terminal A comme auparavant, mais maintenant il n'y a plus de récursion gauche. Cette procédure supprime toutes les récursions gauches immédiates, mais ne supprime pas la récursion gauche impliquant deux étapes ou plus. Étant donné ci-dessous algorithme 4.8 vous permet de supprimer toutes les récursions gauches de la grammaire.
Algorithme 4.8. Suppression de la récursion gauche.
Entrée. KS-grammaire G sans e-règles (de la forme A -> e ).
Sortie. KS-grammar G" sans récursion gauche, équivalent à G.
Méthode. Suivez les étapes 1 et 2.
(1) Disposez les non-terminaux de la grammaire G dans n'importe quel ordre.
(2) Effectuez la procédure suivante :

Après la (i-1)ème itération de la boucle externe à l'étape 2 pour toute règle de la forme ![]() , où k< i
, выполняется s >k. En conséquence, à l'itération suivante (par i), la boucle interne (par j) augmente successivement la limite inférieure de m dans n'importe quelle règle
, où k< i
, выполняется s >k. En conséquence, à l'itération suivante (par i), la boucle interne (par j) augmente successivement la limite inférieure de m dans n'importe quelle règle ![]() , jusqu'à ce qu'il y ait m >= i . Ensuite, après avoir supprimé la récursion immédiate à gauche pour les règles A i, m devient supérieur à i.
, jusqu'à ce qu'il y ait m >= i . Ensuite, après avoir supprimé la récursion immédiate à gauche pour les règles A i, m devient supérieur à i.
Une grammaire contenant une récursion gauche n'est pas une grammaire LL(1). Regardons les règles
UN→ Aa(récursion à gauche dans A)
UN→ un
Ici un symbole prédécesseur pour les deux variantes non terminales UN. De même, une grammaire contenant une boucle récursive gauche ne peut pas être une grammaire LL(1), par exemple
UN→ AVANT JC.
B→ CD
C→ A.E.
Une grammaire contenant une boucle récursive gauche peut être convertie en une grammaire contenant uniquement une récursion directe gauche, puis, en introduisant des non-terminaux supplémentaires, la récursion gauche peut être entièrement éliminée (en effet, elle est remplacée par une récursion droite, ce qui ne pose pas de problème par rapport à LL(1) -propriétés).
A titre d'exemple, considérons une grammaire avec des règles génératives
S→ Aa
UN→ Sib
B→ Cc
C→ Jj
C→ e
D→ Az
qui a une boucle récursive gauche impliquant A B C D. Pour remplacer cette boucle par une récursion directe à gauche, nous ordonnons les non-terminaux comme suit : S, A, B, C, D.
Considérons toutes les règles génératrices de la forme
XI→ Xj γ,
Où XI Et Xj sont des non-terminaux, et γ – une chaîne de caractères terminaux et non terminaux. Concernant les règles pour lesquelles j ≥ je, aucune mesure n'est prise. Cependant, cette inégalité ne peut pas s’appliquer à toutes les règles s’il existe un cycle récursif à gauche. Avec l’ordre que nous avons choisi, nous avons affaire à une seule règle :
D→ Az
parce que UN précédé D dans cet ordre. Commençons maintenant à remplacer UN, en utilisant toutes les règles qui ont UN sur le côté gauche. En conséquence nous obtenons
D→ Bbz
Parce que le B précédé D lors de la commande, le processus est répété, donnant la règle :
D→ CCbz
Puis il se répète et donne deux règles :
D→ ECBZ
D→ Ddcbz
La grammaire convertie ressemble maintenant à ceci :
S→ Aa
UN→ Sib
B→ Cc
C→ Jj
C→ e
D→ Ddcbz
D→ ECBZ
Toutes ces règles génératrices ont la forme requise, et la boucle récursive gauche est remplacée par une récursion directe gauche. Pour éliminer la récursion directe à gauche, nous introduisons un nouveau symbole non terminal Z et changer les règles
D→ ECBZ
D→ Ddcbz
D→ ECBZ
D→ ecbzZ
Z→ DCBZ
Z→ dcbzZ
Notez qu'avant et après la transformation D génère une expression régulière
(ecbz) (dcbz)*
En généralisant, on peut montrer que si un non-terminal UN apparaît sur les côtés gauches r+ s générer des règles, r dont la récursion directe à gauche est utilisée, et s– non, c'est-à-dire
UN→ Aα 1, UN→ Aα 2,..., UN→ Aα r
UN→ β 1, UN→ β 2,..., UN→ β s
alors ces règles peuvent être remplacées par les suivantes :
Une preuve informelle est qu'avant et après la transformation UN génère une expression régulière ( β 1 | β 2 |... | β s) ( α 1 | α 2 |... | α r) *
Il convient de noter qu'en éliminant la récursion gauche (ou boucle récursive gauche), on n'obtient toujours pas une grammaire LL(1), car Pour certains non-terminaux, il existe des côtés droits alternatifs sur le côté gauche des règles des grammaires résultantes, commençant par les mêmes symboles. Par conséquent, après avoir éliminé la récursion gauche, nous devrions continuer à convertir la grammaire sous la forme LL(1).
17.Conversion des grammaires sous la forme LL(1). Factorisation.
Factorisation
Dans de nombreuses situations, les grammaires qui n'ont pas la fonctionnalité LL(1) peuvent être converties en grammaires LL(1) à l'aide du processus de factorisation. Regardons un exemple d'une telle situation.
P.→ commencer D; AVEC fin
D→ d, D
D→ d
AVEC→ s; AVEC
AVEC→ s
Dans le processus de factorisation, nous remplaçons plusieurs règles pour un non-terminal du côté gauche, dont le côté droit commence par le même symbole (chaîne de caractères) par une règle, où du côté droit le début commun est suivi d'un autre introduit non terminal. La grammaire est également complétée par des règles pour un non-terminal supplémentaire, selon lesquelles divers « résidus » du membre droit d'origine de la règle en sont dérivés. Pour la grammaire ci-dessus, cela donnera la grammaire LL(1) suivante :
P.→ commencer D; AVEC fin
D→ dX X)
X→ , D(selon la 1ère règle pour D grammaire originale pour d devrait D)
X→ ε (selon la 2ème règle pour D grammaire originale pour d rien (ligne vide))
AVEC→ s Oui(introduire un non-terminal supplémentaire Oui)
Oui→ ; AVEC(selon la 1ère règle pour C grammaire originale pour s suit ; C)
Oui→ ε (selon la 2ème règle pour C grammaire originale pour s rien (ligne vide))
De même, les règles génératives
S→ asb
S→ asc
S→ ε
peut être converti par factorisation en règles
S→ aSX
S→ ε
X→ b
X→ c
et la grammaire résultante est LL(1). Le processus de factorisation ne peut cependant pas être automatisé en l’étendant au cas général. L'exemple suivant montre ce qui peut arriver. Regardons les règles
1. P.→ Qx
2. P.→ Ry
3. Q→ m²
4. Q→ q
5. R.→ sRN
6. R.→ r
Les deux jeux de caractères guides pour deux options P. contenir s, et en essayant de "endurer s entre parenthèses", nous remplaçons Q Et R.à droite des règles 1 et 2 :
P.→ sQmx
P.→ sRny
P.→ qx
P.→ ry
Ces règles peuvent être remplacées par les suivantes :
P.→ qx
P.→ ry
P.→ SP 1
P. 1 → Qmx
P. 1 → Rny
Règles pour P1 semblable aux règles originales pour P. et avoir des ensembles de personnages guides qui se croisent. Nous pouvons transformer ces règles de la même manière que les règles de P.:
P. 1 → sQmmx
P. 1 → qmx
P. 1 → srnny
P. 1 → rny
En factorisant, on obtient
La procédure d'analyse récursive descendante peut provoquer un problème de boucle infinie.
Dans une grammaire pour opérations arithmétiques, l’application de la deuxième règle entraînera une boucle dans la procédure d’analyse. De telles grammaires sont dites récursives à gauche. Une grammaire est dite récursive à gauche si elle contient un A non terminal pour lequel il existe une conclusion A=>+Aa. Dans les cas simples, la récursion à gauche est provoquée par des règles de la forme
Dans ce cas, un nouveau non-terminal est introduit et les règles originales sont remplacées par les suivantes.
(s'il existe un non-terminal A pour lequel il existe une conclusion A→+Aa en 1 ou plusieurs étapes). La récursion à gauche peut être évitée en transformant la grammaire.
Par exemple, les produits A→Aa
Peut être remplacé par des équivalents :
Pour un tel cas, il existe un algorithme qui élimine la récursion gauche :
1) nous définissons un certain ordre sur l'ensemble des non-terminaux (A 1, A 2, ..., A n)
2) prendre chaque non-terminal s'il existe une production pour lui qui prend en compte le non-terminal de gauche, et transformer la grammaire :
pour i:=1 à n faire
pour j:=1 à i-1 faire
si Ai → Ajγ alors Ai→δ1γ
│ δkγ, où
Aj → δ1│ δ2│ …│ δk
3) exclure tous les cas de récursion immédiate à gauche (règle 1)
Que. L'algorithme permet d'éviter les boucles.
Exclure la récursion gauche de la grammaire des expressions arithmétiques et de la forme générale de la règle d'élimination de la récursion gauche :
Vue générale de la règle d'élimination de la récursivité gauche
Factorisation à gauche.
Les grammaires LL(1) sont nécessaires afin de sélectionner les produits souhaités pour une analyse descendante, afin qu'aucune boucle ne se produise.
Parfois, il est possible de convertir la grammaire sous la forme LL(1) en utilisant la méthode de factorisation à gauche.
Par exemple : S→ si B alors S
│si B alors S sinon S
Ces productions violent la condition des grammaires LL(1). Cette grammaire peut être convertie sous la forme LL(1).
S → si B alors S Queue
DANS vue générale cette transformation peut être définie ainsi :
nous introduisons un nouveau non-terminal B, pour lequel
| β N Pour B nous pouvons appliquer la factorisation à gauche. Cette procédure est répétée tant que le choix du produit reste incertain (c'est-à-dire tant que quelque chose peut y être modifié).
Construction du PREMIER ensemble
Le Premier ensemble pour un non-terminal définit l'ensemble de terminaux à partir duquel ce non-terminal peut partir.
1. Si x est un terminal, alors first(x)=(x). Puisque le premier caractère d’une séquence provenant d’un terminal ne peut être que le terminal lui-même.
2. Si la grammaire contient la règle Xà e, alors l'ensemble first(x) inclut e. Cela signifie que X peut commencer par une séquence vide, c’est-à-dire être totalement absente.
3. Pour tous les produits de la forme XàY1 Y2 … Yk nous effectuons ce qui suit. Nous ajoutons l'ensemble first(Yi) à l'ensemble first(X) jusqu'à ce que first(Yi-1) contienne e et first(Yi) ne contienne pas e. Dans ce cas, i passe de 0 à k. Ceci est nécessaire car si Yi-1 peut manquer, alors il est nécessaire de savoir où commencera toute la séquence dans ce cas.
Propriété LL(k) impose de grandes restrictions à la grammaire. Parfois, il est possible de transformer une grammaire de telle sorte que la grammaire résultante ait propriété LL(1) . Une telle transformation ne réussit pas toujours, mais s'il est possible d'obtenir une grammaire LL(1), alors pour construire un analyseur, vous pouvez utiliser la méthode de descente récursive sans revenir en arrière.
Supposons que nous devions créer un analyseur pour un langage généré par la grammaire suivante :
E → E + T | E – T | T
T → T * F | V/F | F
F → num | (E)
Plusieurs terminaux PREMIER(T) appartiennent également à l'ensemble PREMIER(E+T), il est donc impossible de déterminer sans ambiguïté la séquence d'appels de procédure qui doit être effectuée lors de l'analyse de la chaîne d'entrée. Le problème est que le non-terminal E se produit dans la première position du côté droit de la règle, dont le côté gauche est également E. Dans une telle situation, le non-terminal E est appelé récursif directement gauche.
Non terminal UN Grammaires KS g appelé gauche récursive , s'il y a une conclusion dans la grammaire UN =>* Oh.
Une grammaire qui a au moins une règle récursive gauche ne peut pas être LL(1)-grammaire.
D’autre part, on sait que tout langage CS est défini par au moins une grammaire récursive non gauche.
Algorithme pour éliminer la récursivité gauche
Laisser G = (N, T, P, S)– Grammaire et règle KS A → Aw 1 | Oh 2 | ... | Oh n | v 1 | v 2 | ... | v m représente toutes les règles de P. contenant UN sur le côté gauche, et aucune des chaînes v je ne commence pas par un non-terminal UN.
Ajoutons à l'ensemble N un autre non-terminal UN" et remplacer les règles contenant UN sur le côté gauche, à ce qui suit :
UNE → v 1 | v 2 | ... | v m | v 1 UN' | v 2 Un' | ... | v m UN"
A' → w 1 | w 2 | ... | w n | w 1 Un' | w 2 Un' | ...| w n UN"
On peut prouver que la grammaire résultante est équivalente à celle d’origine.
En appliquant cette transformation à la grammaire ci-dessus décrivant des expressions arithmétiques, nous obtenons la grammaire suivante :
E → T | T.E."
E" → + T | + T.E."
T → F | F.T."
T"→ * F | * F.T."
F → (E) | num
Il est facile de montrer que la grammaire résultante a la propriété LL(1).
Un autre problème similaire se produit lorsque deux règles pour le même non-terminal commencent par les mêmes caractères.
Par exemple,
S → si E alors S sinon S
S → si E alors S
Dans ce cas, nous ajouterons un autre non-terminal qui correspondra aux différentes terminaisons de ces règles. Nous obtenons les règles suivantes :
S → si E alors S S’
S" →
S"→ autre S
Pour la grammaire résultante, la méthode de descente récursive peut être implémentée.
9.1.4. Descente récursive avec retours.
Afin de pouvoir appliquer la méthode de descente récursive, il faut 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 transformer la grammaire en une forme dans laquelle des ensembles D'ABORD ne se croisent pas, ce qui est un processus complexe, donc en pratique une technique appelée descente récursive avec retours .
Pour ce faire, l'analyseur lexical est représenté comme un objet qui, en plus des méthodes traditionnelles analyse, suivant etc., il existe également un constructeur de copie. Ensuite, dans toutes les situations où une ambiguïté peut survenir, avant de commencer l'analyse, vous devez vous souvenir de l'état actuel de l'analyseur lexical (c'est-à-dire faire une copie de l'analyseur lexical) et continuer l'analyse du texte, en considérant qu'il s'agit du premier des les constructions possibles dans cette situation. Si cette option d'analyse échoue, vous devez alors restaurer l'état de l'analyseur lexical et essayer d'analyser à nouveau le même fragment en utilisant option suivante grammaire, etc. Si toutes les options d'analyse échouent, une erreur est signalée.
Cette méthode d'analyse est potentiellement plus lente que la descente récursive sans retour en arrière, mais dans ce cas parvient à garder la grammaire dans son forme originale et économisez les efforts du programmeur.