
Классификация формальных грамматик по Хомскому
· Грамматика типа 0 (общего вида). Правила имеют вид α→β
· Грамматика типа 1 (контекстно зависимая, КЗ)
Правила имеют вид αAβ → αγβ. γ принадлежит V + , т.е. грамматика является неукорачивающей
α,β называются левым и правым контекстом
· Грамматика типа 2 (контекстно свободная, КС)
Правила имеют вид A → α. α принадлежит V*, т.е. грамматика может быть укорачивающей => КС языки не содержатся в КЗ
Наиболее близкая к БНФ
· Грамматика типа 3 (автоматная, регулярная)
Правила имеют вид A → aB, A → a, A → ε
Автоматные языки содержатся в КС языках
Пример. Грамматика, порождающая язык правильных скобочных выражений.
S → (S) | SS | ε
Порождение (вывод)
Обозначения
=>+ (1 или более)
=>* (0 или более)
Сентенциальная форма грамматики— это строка, которая может быть выведена из стартового символа.
Предложение (сентенция) грамматики— это сентенциальная форма, состоящая из одних терминалов.
Язык L(G) грамматики— это множество всех ее предложений.
Обозначения:
Левый, правый вывод (порождение).
Левый и правый вывод для предложения i + i * i
Дерево вывода (синтаксическое дерево, дерево разбора) строки предложения. В отличие от порождения, из него исключена информация о порядке вывода.
Крона дерева разбора — цепочка меток листьев слева направо
Грамматика, которая дает более одного дерева разбора для некоторого предложения, называется неоднозначной.
Пример неоднозначной грамматики. Грамматика арифметических выражений.
E → E+E | E*E | i
Два дерева разбора для цепочки i + i * i
Пример неоднозначной грамматики. Грамматика условного оператора
S → if b then S
| if b then S else S
Два дерева разбора для цепочки if b then if b then a
Преобразование в эквивалентную однозначную грамматику:
S → if b then S
| if b then S2 else S
S2 → if b then S2 else S2
44.Формальные языки и грамматики: непустые, конечные и бесконечные языки

45.Эквивалентность и минимизация автоматов
Эквивалентность конечных автоматов
Пусть S — алфавит (конечное множество символов) и S* — множество всех слов в алфавите S. Будем обозначать буквой eпустое слово, т.е. вовсе не содержащее букв (символов из S), а знаком × — операцию приписывания (конкатенации) слов.
Так, аав × ва = аавва. Знак × операции приписывания часто опускают.
Слова в алфавите S будем обозначать малыми греческими буквами a, b, g, …. Очевидно, e является единицей для операции приписывания:
Очевидно также, что операция приписывания ассоциативна, т.е. (ab)g = a(bg).
Таким образом, множество S* всех слов в алфавите S относительно операции приписывания является полугруппой с единицей, т.е. моноидом;
S* называют свободным моноидом над алфавитом S.
Минимизация конечного автомата
Разные конечные автоматы могут функционировать одинаково, даже если у них разное число состояний. Важной задачей является нахождение минимального конечного автомата, который реализует заданное автоматное отображение .
Эквивалентными естественно назвать два состояния автомата, которые нельзя различить никакими входными словами.
Определение 1: Два состояния р и q конечного автомата
А = (S,X,Y,s0,d,l) называются эквивалентными (обозначается p~q), если («aÎ X*)l*(p,a) =l*(q, a)
46.Эквивалентность одноленточных и многоленточных машин Тьюринга
Очевидно, что понятие k–ленточной МТ шире, чем понятие «обычной» одноленточной машины. ОПРЕДЕЛЕНИЕ 6. (k+1)–ленточная МТ M′ с программой w симулирует k–ленточную машину M, если для любого набора входных слов (x1, x2, …, xk) результат работы M′ совпадает с результатом работы M на этих же входных данных. Предполагается, что вначале слово w записано на (k+1)-й ленте M′. Под результатом понимается состояние первых k лент МТ в момент остановки, а если на данном входе M не останавливается, то симулирующая ее машина также не должна останавливаться на данном входе.
ОПРЕДЕЛЕНИЕ 7. (k+1)–ленточная МТ M* называется универсальной машиной Тьюринга для k–ленточных машин, если для любой k- ленточной машины M существует программа w, на которой M* симулирует M. 12 Обратите внимание: в определении универсальной МТ одна и та же машина M′ должна симулировать разные k-ленточные машины (на разных программах w). Рассмотрим следующую теорему . ТЕОРЕМА 3. Для любого k≥1 существует универсальная (k+1)– ленточная машина Тьюринга. Доказательство. Теорему докажем конструктивно, т.е. покажем, как можно построить требуемую универсальную машину M*. Рассмотрим лишь общую схему построения, опустив сложные детали. Основная идея заключается в том, чтобы на дополнительную (k+1)-ю ленту разместить описание симулируемой машины Тьюринга и использовать это описание в процессе симулирования.
ОПРЕДЕЛЕНИЕ 8. Будем говорить, что машина Тьюринга M вычисляет частичную функцию f:A*→A*, если для любого x∈A*, записанного на первую ленту машины M: если f(x) определено, то M останавливается, и в момент остановки на последней ленте машины записано слово f(x); если f(x) не определено, то машина M не останавливается.
ОПРЕДЕЛЕНИЕ 9. Будем говорить, что машины M и M′ эквивалентны, если они вычисляют одну и ту же функцию. Понятие эквивалентности «слабее», чем симулирование: если машина M′ симулирует машину M, то машина M′ эквивалентна M; обратное, вообще говоря, неверно. С другой стороны, для симулирования требуется, чтобы у M′ было как минимум столько же лент, сколько и у M, в то время как для эквивалентности это не 15 обязательно. Именно это свойство позволяет нам сформулировать и доказать следующую теорему .
ТЕОРЕМА 4. Для любой k-ленточной машины M, имеющей временную сложность T(n), существует эквивалентная ей одноленточная машина M′ с временной сложностью T′ (n) = O(T 2 (n)).
48.Эквивалентные преобразования КС-грамматик: исключение цепных правил, удаление произвольного правила грамматики
Определение. Правило грамматики вида , где , V A , называется цепным.
Утверждение. Для КС-грамматики Г, содержащей цепные правила, можно построить эквивалентную ей грамматику Г», не содержащую цепных правил.
Идея доказательства заключается в следующем. Если схема грамматики имеет вид
R = {…, ,…, , … , a },
то такая грамматика эквивалентна грамматике со схемой
R» = {…, a,…},
поскольку вывод в грамматике со схемой R цепочки a:
может быть получен в грамматике со схемой R» с помощью правила a.
В общем случае доказательство последнего утверждения можно выполнить так. Разобьем R на два подмножества R 1 и R 2 , включая в R 1 все правила вида
Для каждого правила из R 1 найдем множество правил S(), которые строятся так:
если * и в R 2 есть правило α, где α — цепочка словаря (V т V A)*, то в S() включим правило α.
Построим новую схему R» путем объединения правил R 2 и всех построенных множеств S(). Получим грамматику Г» = {V т, V A , I, R»}, которая эквивалентна заданной и не содержит правил вида .
В качестве примера выполним исключение цепных правил из грамматики Г 1.9 со схемой:
R={+|,
*|,
()|a }
Вначале разобьем правила грамматики на два подмножества:
R 1 = { , },
R 2 = { +, *, ()|a }
Для каждого правила из R 1 построим соответствующее подмножество.
S() = { *, ()|a },
S() = { ()|a}
В результате получаем искомую схему грамматики без цепных правил в виде:
R 2 U S() U S() = { + | * | () | a,
* | () | a,
() | a }
Последний вид рассматриваемых преобразований связан с удалением из грамматики правил с пустой правой частью.
Определение. Правило вида $ называется аннулирующим правилом.
49.Эквивалентные преобразования КС-грамматик: удаление бесполезных символов.
Пусть дана произвольная КС-грамматика G. Нетерминал A этой грамматики называется продуктивным, если существует такая терминальная цепочка (в том числе и пустая), что A Þ * a непродуктивным.
Теорема. Каждая КС-грамматика эквивалентна КС-грамматике без непродуктивных нетерминалов.
Нетерминал A грамматики G называется достижимым, если существует такая цепочка a, что S Þ * a. В противном случае нетерминал называется недостижимым.
Теорема. Каждая КС-грамматика эквивалентна КС-грамматике без недостижимых нетерминалов.
Нетерминальный символ в КС-грамматике называется бесполезным (или лишним), если он либо недостижим, либо непродуктивен.
Теорема. Каждая КС-грамматика эквивалентна КС-грамматике, в которой нет бесполезных нетерминалов.
Пример. Устраним бесполезные символы в грамматике
S® aC | A; A® cAB; B® b ; C® a .
Шаг 1. Строим множество достижимых символов: {S} ® {S, C, A}® {S, C, A, B}.Все нетерминалы достижимы. Недостижимых нет грамматика не меняется.
Шаг 2. Строим множество продуктивных символов: { C, B}® {S, C, B}.Получаем, что A— не продуктивен. Выкидываем его и все правила с ним из грамматики. Получим
S® aC ; B® b ; C® a .
Шаг 3. Строим множество достижимых символов новой грамматики: {S} ® {S, C}.Получаем, что B недостижим. Выкидываем его и все правила с ним из грамматики. Получим
S® aC ; C® a .
Это — окончательный результат.
50. Эквивалентные преобразования КС-грамматик: устранение левой рекурсии, левая факторизация
Удаление левой рекурсии
Основная трудность при использовании предсказывающего анализа — это нахождение такой грамматики для входного языка, по которой можно построить таблицу анализа с однозначно определенными входами. Иногда с помощью некоторых простых преобразований грамматику, не являющуюся LL(1), можно привести к эквивалентной LL(1)-грамматике. Среди этих преобразований наиболее эффективными являются левая факторизация и удаление левой рекурсии. Здесь необходимо сделать два замечания. Во-первых, не всякая грамматика после этих преобразований становится LL(1), и, во-вторых, после таких преобразований получающаяся грамматика может стать менее понимаемой.
Непосредственную левую рекурсию, то есть рекурсию вида , можно удалить следующим способом. Сначала группируем A -правила:
где никакая из строк не начинается с A. Затем заменяем этот набор правил на
![]()
где A» — новый нетерминал. Из нетерминала A можно вывести те же цепочки, что и раньше, но теперь нет левой рекурсии. С помощью этой процедуры удаляются все непосредственные левые рекурсии, но не удаляется левая рекурсия, включающая два или более шага. Приведенный ниже алгоритм 4.8 позволяет удалить все левые рекурсии из грамматики.
Левая факторизация
Oсновная идея левой факторизации в том, что в том случае, когда неясно, какую из двух альтернатив надо использовать для развертки нетерминала A, нужно изменить A -правила так, чтобы отложить решение до тех пор, пока не будет достаточно информации для принятия правильного решения.
Если ![]() — два A -правила и входная цепочка начинается с непустой строки, выводимой из мы не знаем, разворачивать ли по первому правилу или по второму. Можно отложить решение, развернув . Тогда после анализа того, что выводимо из можно развернуть по или по . Левофакторизованные правила принимают вид
— два A -правила и входная цепочка начинается с непустой строки, выводимой из мы не знаем, разворачивать ли по первому правилу или по второму. Можно отложить решение, развернув . Тогда после анализа того, что выводимо из можно развернуть по или по . Левофакторизованные правила принимают вид
![]()
51.Язык машины Тьюринга.
В состав машины Тьюринга входит неограниченная в обе стороны лента (возможны машины Тьюринга, которые имеют несколько бесконечных лент), разделённая на ячейки, и управляющее устройство (также называется головкой записи-чтения (ГЗЧ)), способное находиться в одном из множества состояний. Число возможных состояний управляющего устройства конечно и точно задано.
Управляющее устройство может перемещаться влево и вправо по ленте, читать и записывать в ячейки символы некоторого конечного алфавита. Выделяется особыйпустой символ, заполняющий все клетки ленты, кроме тех из них (конечного числа), на которых записаны входные данные.
Управляющее устройство работает согласно правилам перехода, которые представляют алгоритм, реализуемый данной машиной Тьюринга. Каждое правило перехода предписывает машине, в зависимости от текущего состояния и наблюдаемого в текущей клетке символа, записать в эту клетку новый символ, перейти в новое состояние и переместиться на одну клетку влево или вправо. Некоторые состояния машины Тьюринга могут быть помечены как терминальные, и переход в любое из них означает конец работы, остановку алгоритма.
Машина Тьюринга называется детерминированной, если каждой комбинации состояния и ленточного символа в таблице соответствует не более одного правила. Если существует пара «ленточный символ — состояние», для которой существует 2 и более команд, такая машина Тьюринга называется недетерминированной.
LL(k)- грамматикой,если для данной цепочки и первых kсимволов (если они есть), выводящихся из , существуетне более одного правила, которое можно применить к A,чтобы получить вывод какой-нибудь терминальной цепочки,

Рис. 4.4.
начинающейся с и продолжающейся упомянутыми kтерминалами.
Грамматика называется LL(k)-грамматикой, если она LL(k)- грамматика для некоторого k.
Пример 4.7. Рассмотрим грамматику G = ({S, A, B}, {0, 1,a, b}, P, S), где P состоит из правил
S -> A | B, A -> aAb | 0, B -> aBbb | 1.
Здесь . G не является LL(k)-грамматикой ни для какого k. Интуитивно, если мыначинаем с чтения достаточно длинной цепочки, состоящей изсимволов a, то не знаем, какое из правил S -> A и S -> B было применено первым, пока не встретим 0 или 1.
Обращаясь к точному определению LL(k)-грамматики,положим и y = a k 1b 2k.Тогда выводы

соответствуют выводам (1) и (2) определения. Первые k символовцепочек x и y совпадают. Однако заключение ложно. Так как k здесь выбрано произвольно, то G не является LL-грамматикой.
Следствия определения LL(k)-грамматики
Теорема 4.6. КС-грамматика является LL(k)-грамматикой тогда и только тогда, когда для двухразличных правил и из Р пересечение пусто при всех таких ,что ![]() .
.
Доказательство. Необходимость. Допустим, что и удовлетворяют условиям теоремы, а содержит x. Тогда по определению FIRST длянекоторых y и zнайдутся выводы

(Заметим, что здесь мы использовали тот факт, что N несодержит бесполезных нетерминалов, как это предполагаетсядля всех рассматриваемых грамматик.) Если |x|
Достаточность. Допустим, что G не LL(k)- грамматика.
Тогда найдутся такие два вывода
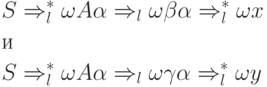
что цепочки x и y совпадают в первых k позициях, но . Поэтому и — различные правила из P и каждоеиз множеств ![]() и
и ![]() содержит цепочку FIRST k (x), совпадающую с цепочкой FIRST k (y).
содержит цепочку FIRST k (x), совпадающую с цепочкой FIRST k (y).
Пример 4.8. Грамматика G, состоящая из двух правил S ->aS | a, не будет LL(1)-грамматикой, так как
FIRST 1 (aS) = FIRST 1 (a) = a.
Интуитивно это можно объяснить так: видя при разборецепочки, начинающейся символом a, только этот первый символ,мы не знаем, какое из правил S -> aS или S -> a надо применитьк S. С другой стороны, G — это LL(2)- грамматика. В самом деле, вобозначениях только что представленной теоремы, если ![]() , то A = S и . Так как для S даны только два указанных правила, то и . Поскольку FIRST2(aS) = aa и FIRST2(a) = a, то по последней теореме G будет LL(2)-грамматикой.
, то A = S и . Так как для S даны только два указанных правила, то и . Поскольку FIRST2(aS) = aa и FIRST2(a) = a, то по последней теореме G будет LL(2)-грамматикой.
Удаление левой рекурсии
Основная трудность при использованиипредсказывающего анализа — это нахождение такойграмматики для входного языка, по которой можнопостроить таблицу анализа с однозначно определеннымивходами. Иногда с помощью некоторых простыхпреобразований грамматику, не являющуюся LL(1), можнопривести к эквивалентной LL(1)-грамматике. Среди этихпреобразований наиболее эффективными являются леваяфакторизация и удаление левой рекурсии. Здесь необходимосделать два замечания. Во-первых, не всякая грамматикапосле этих преобразований становится LL(1), и, во-вторых,после таких преобразований получающаяся грамматикаможет стать менее понимаемой.
Непосредственную левую рекурсию, то есть рекурсиювида , можно удалить следующим способом. Сначалагруппируем A -правила:
где никакая из строк не начинается с A. Затем заменяем этот набор правил на
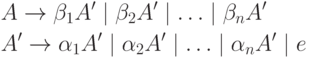
где A» — новый нетерминал. Из нетерминала A можновывести те же цепочки, что и раньше, но теперь нет левой рекурсии. С помощью этой процедуры удаляются всенепосредственные левые рекурсии, но не удаляется леваярекурсия, включающая два или более шага. Приведенныйниже алгоритм 4.8 позволяет удалить все левые рекурсии изграмматики.
Алгоритм 4.8. Удаление левой рекурсии.
Вход. КС-грамматика G без e-правил (вида A -> e).
Выход. КС-грамматика G» без левой рекурсии,эквивалентная G.
Метод. Выполнить шаги 1 и 2.
(1) Упорядочить нетерминалы грамматики G в произвольномпорядке.
(2) Выполнить следующую процедуру:

После (i-1) -й итерации внешнего цикла на шаге 2 длялюбого правила вида ![]() , где k k.В результате на следующей итерации (по i) внутренний цикл(по j) последовательно увеличивает нижнюю границу по m влюбом правиле
, где k k.В результате на следующей итерации (по i) внутренний цикл(по j) последовательно увеличивает нижнюю границу по m влюбом правиле ![]() , пока не будет m >= i. Затем, после удаления непосредственной левой рекурсии для A i -правил, m становится больше i.
, пока не будет m >= i. Затем, после удаления непосредственной левой рекурсии для A i -правил, m становится больше i.
Грамматика, содержащая левую рекурсию, не является LL(1)- грамматикой. Рассмотрим правила
A→ Aa(левая рекурсия в A)
A→ a
Здесь aсимвол-предшественник для обоих вариантов нетерминала A. Аналогично грамматика, содержащая левый рекурсивный цикл, не может быть LL(1)-грамматикой, например
A→ BC
B→ CD
C→ AE
Грамматику, содержащую левый рекурсивный цикл, можно преобразовать в грамматику, содержащую только прямую левую рекурсию, и далее, за счет введения дополнительных нетерминалов, левую рекурсию можно исключить полностью (в действительности она заменяется правой рекурсией, которая не представляет проблемы в отношении LL(1)-свойства).
В качестве примера рассмотрим грамматику с порождающими правилами
S→ Aa
A→ Bb
B→ Cc
C→ Dd
C→ e
D→ Az
которая имеет левый рекурсивный цикл, вовлекающий A, B, C, D. Чтобы заменить этот цикл прямой левой рекурсией, упорядочим нетерминалы следующим образом: S, A, B, C, D.
Рассмотрим все порождающие правила вида
Xi→ Xj γ,
где Xiи Xj– нетерминалы, а γ– строка терминальных и нетерминальных символов. В отношении правил, для которых j ≥ i, никакие действия не производятся. Однако это неравенство не может выдерживаться для всех правил, если есть левый рекурсивный цикл. При выбранном нами порядке мы имеем дело с единственным правилом:
D→ Az
так как Aпредшествует Dв этом упорядочении. Теперь начнем замещать A, пользуясь всеми правилами, имеющими Aв левой части. В результате получаем
D→ Bbz
Поскольку Bпредшествует Dв упорядочении, процесс повторяется, что дает правило:
D→ Ccbz
Затем он повторяется еще раз и дает два правила:
D→ ecbz
D→ Ddcbz
Теперь преобразованная грамматика выглядит следующим образом:
S→ Aa
A→ Bb
B→ Cc
C→ Dd
C→ e
D→ Ddcbz
D→ ecbz
Все эти порождающие правила имеют требуемый вид, а левый рекурсивный цикл заменен прямой левой рекурсией. Чтобы исключить прямую левую рекурсию, введем новый нетерминальный символ Zи заменим правила
D→ ecbz
D→ Ddcbz
D→ ecbz
D→ ecbzZ
Z→ dcbz
Z→ dcbzZ
Заметим, что до и после преобразования Dгенерирует регулярное выражение
(ecbz) (dcbz)*
Обобщая, можно показать, что если нетерминал Aпоявляется в левых частях r+ sпорождающих правил, rиз которых используют прямую левую рекурсию, а s– нет, т.е.
A→ Aα1, A→ Aα2,…, A→ Aαr
A→ β1, A→ β2,…, A→ βs
то эти правила можно заменить на следующие:
Неформальное доказательство заключается в том, что до и после преобразования Aгенерирует регулярное выражение (β1 | β2 |… | βs) (α1 | α2 |… | αr) *
Следует обратить внимание, что устранив левую рекурсию (или левый рекурсивный цикл), мы еще не получаем LL(1)-грамматику, т.к. для некоторых нетерминалов в левой части правил полученных грамматик существуют альтернативные правые части, начинающиеся с одних и тех же символов. Поэтому после устранения левой рекурсии следует продолжить преобразование грамматики к LL(1) виду.
17.Преобразование грамматик в LL(1) форму. Факторизация.
Факторизация
Во многих ситуациях грамматики, не обладающие признаком LL(1), можно преобразовать в LL(1)-грамматики с помощью процесса факторизации. Рассмотрим пример такой ситуации.
P→ begin D; Сend
D→ d, D
D→ d
С→ s; С
С→ s
В процессе факторизации мы заменяем несколько правил для одного нетерминала в левой части, правая часть которых начинается с одного и того же символа (цепочки символов) на одно правило, где в правой части за общим началом следует дополнительно вводимый нетерминал. Также грамматика дополняется правилами для дополнительного нетерминала, согласно которым из него выводятся различные «остатки» первоначальной правой части правила. Для приведенной выше грамматики это даст следующую LL(1)-грамматику:
P→ begin D; Сend
D→ d X X)
X→ , D(по 1-му правилу для Dисходной грамматики за dследует, D)
X→ ε(по 2-му правилу для Dисходной грамматики за dничего нет (пустая строка))
С→ s Y(вводим дополнительный нетерминал Y)
Y→ ; С(по 1-му правилу для Cисходной грамматики за sследует; C)
Y→ ε(по 2-му правилу для Cисходной грамматики за sничего нет (пустая строка))
Аналогичным образом, порождающие правила
S→ aSb
S→ aSc
S→ ε
можно преобразовать путем факторизации в правила
S→ aSX
S→ ε
X→ b
X→ c
и полученной в результате грамматикой будет LL(1). Процесс факторизации, однако, нельзя автоматизировать, распространив его на общий случай. Следующий пример показывает, что может произойти. Рассмотрим правила
1. P→ Qx
2. P→ Ry
3. Q→ sQm
4. Q→ q
5. R→ sRn
6. R→ r
Оба множества направляющих символов для двух вариантов Pсодержат s, и, пытаясь «вынести sза скобки», мы замещаем Qи Rв правыхчастях правил 1 и 2:
P→ sQmx
P→ sRny
P→ qx
P→ ry
Эти правила можно заменить следующими:
P→ qx
P→ ry
P→ sP1
P1 → Qmx
P1 → Rny
Правила для P1аналогичны первоначальным правилам для Pи имеют пересекающиеся множества направляющих символов. Мы можем преобразовать эти правила так же, как и правила для P:
P1 → sQmmx
P1 → qmx
P1 → sRnny
P1 → rny
Факторизуя, получаем
При процедуре рекурсивного разбора сверху вниз может возникнуть проблема бесконечного цикла.
В грамматике для арифметических операций применение второго правила приведет к зацикливанию процедуры разбора. Подобные грамматики называются леворекурсивными. Грамматика называется леворекурсивной, если в ней существует нетерминал А, для которого существует вывод А=>+Аa. В простых случаях левая рекурсия вызвана правилами вида
В этом случае вводят новый нетерминал и исходные правила заменяют следующими.
(если есть нетерминал А, для которого существует вывод А→+Аa за 1 или более шагов). Левой рекурсии можно избежать, преобразовав грамматику.
Например, продукции A→Aa
Можно заменить на эквивалентные:
Для такого случая существует алгоритм, исключающий левую рекурсию:
1) определяем на множестве нетерминалов какой-либо порядок (А 1 , А 2 , …, А n)
2) берем каждый нетерминал, если для него есть продукция, учитывающая нетерминал, стоящий левее, и преобразуем грамматику:
for i:=1 to n do
for j:=1 to i-1 do
if Ai → Ajγ then Ai→δ1γ
│ δkγ, где
Aj → δ1│ δ2│ …│ δk
3) исключаем все случаи непосредственной левой рекурсии (правило1)
Т.о. алгоритм помогает избежать зацикливания.
Исключение левой рекурсии из грамматики арифметических выражений и общий вид правила исключения левой рекурсии:
Общий вид правила исключения левой рекурсии
Левая факторизация.
LL(1)-грамматики нужны для того, чтобы выбрать нужную продукцию для разбора сверху-вниз, чтобы не произошло зацикливание.
Иногда существует возможность преобразовать грамматику к LL(1) виду, используя метод левой факторизации.
Например: S→ if B then S
│if B then S else S
Эти продукции нарушают условие LL(1)-грамматик. Эту грамматику можно преобразовать к виду LL(1).
S → if B then S Tail
В общем виде это преобразование можно определить так:
вводим новый нетерминал В, для которого
| β N Для B можно применить левую факторизацию. Эта процедура повторяется, пока остается неопределенным выбор продукции (т.е. пока в ней можно что-нибудь изменить).
Построение множества FIRST
Множество First для нетерминала определяет множество терминалов, с которых может начинаться данный нетерминал.
1. Если х — терминал, то first(x)={x}. Так как первым символом последовательности из одного терминала может являться только сам терминал.
2. Если в грамматике присутствует правило Хà e, то множество first(х) включает e. Это означает, что Х может начинаться с пустой последовательности, то есть отсутствовать вообще.
3. Для всех продукций вида XàY1 Y2 … Yk выполняем следующее. Добавляем в множество first(Х) множество first(Yi) до тех пор, пока first(Yi-1) содержит e, а first(Yi) не содержит e. При этом i изменяется от 0 до k. Это необходимо, так как если Yi-1 может отсутствовать, то необходимо выяснить, с чего будет начинаться вся последовательность в этом случае.
LL(k)-свойствонакладывает большие ограничения награмматику. Иногда имеется возможностьпреобразовать грамматику так, чтобыполучившаяся грамматика обладаласвойствомLL(1).Такое преобразование далеко не всегдаудается, но если удалось получитьLL(1)-грамматику, то для построенияанализатора можно использовать методрекурсивного спуска без возвратов.
Предположим,что необходимо построить анализаторязыка, порождаемого следующей грамматикой:
E→E+T|E–T|T
T→ T * F | T / F | F
F→num| (E)
Терминалымножества FIRST(T)принадлежат также множеству FIRST(E+T),поэтому нельзя однозначно определитьпоследовательность вызовов процедур,которую необходимо выполнить при анализевходной цепочки. Проблема заключаетсяв том, что нетерминал Eвстречаетсяна первой позиции правой части правила,левая часть которого также E.В такой ситуации нетерминалEназывается непосредственно леворекурсивным.
НетерминалAКС-грамматики Gназывается леворекурсивным,если в грамматике существует вывод A=>*Aw.
Грамматика,имеющая хотя бы одно леворекурсивноеправило, не может быть LL(1)-грамматикой.
Сдругой стороны, известно, что каждыйКС-язык определяется хотя бы однойнелеворекурсивной грамматикой.
-
Алгоритм устранения леворекурсивности
ПустьG= (N, T, P, S)– КС-грамматика и правило A→Aw 1 | Aw 2 | … | Aw n | v 1 |v 2 | … | v mпредставляет собой все правила из P,содержащие Aв левой части, причем ни одна из цепочекv iне начинается с нетерминала A.
Добавимк множеству Nеще один нетерминал A»и заменим правила, содержащие Aв левой части, на следующие:
A→ v 1 |v 2 | … | v m | v 1 A’ |v 2 A’ | … | v m A»
A’→ w 1 | w 2 | … | w n | w 1 A’ | w 2 A’ | …|w n A»
Можнодоказать, что полученная грамматикаэквивалентна исходной.
Врезультате применения этого преобразованияк приведенной выше грамматике, описывающейарифметические выражения, получимследующую грамматику:
E→T|TE«
E«→ +T| +TE«
T →F|FT«
T«→*F| *FT«
F→ (E)|num
Нетруднопоказать, что получившаяся грамматикаобладает свойством LL(1).
Ещеодна подобная проблема связана с тем,что два правила для одного и того женетерминала начинаются одними и темиже символами.
Например,
S→ if E then S else S
S→ifEthenS
Вэтом случае добавим еще один нетерминал,который будет соответствовать различнымокончаниям этих правил. Получим следующиеправила:
S→ifEthenSS’
S«→
S«→elseS
Дляполученной грамматики может бытьреализован метод рекурсивного спуска.
-
9.1.4. Рекурсивный спуск с возвратами.
Длятого, чтобы иметь возможность применитьметод рекурсивного спуска,необходимоы 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0преобразовать грамматику к виду, вкотором множества FIRSTне пересекаются, что является сложнымпроцессом, поэтому на практике используетсяприем, называемый рекурсивнымспуском с возвратами.
Дляэтого лексический анализатор представляетсяв виде объекта, у которого помимотрадиционных методов scan,nextит. д., есть также копирующий конструктор.Затем во всех ситуациях, где можетвозникнуть неоднозначность, передначалом разбора надо запомнить текущеесостояние лексического анализатора(т. е. сделать копию лексическогоанализатора) и продолжить разбор текста,считая, что имеем дело с первой извозможных в данной ситуации конструкций.Если этот вариант разбора заканчиваетсянеудачей, то надо восстановить состояниелексического анализатора и пытатьсязаново разобрать тот же самый фрагментс помощью следующего варианта грамматикии т. д. Если все варианты разборазаканчиваются неудачно, то сообщаетсяоб ошибке.
Такойметод разбора потенциально медленнее,чем рекурсивный спуск без возвратов,но в данном случае удается сохранитьграмматику в ее оригинальном виде исэкономить усилия программиста.