Što je statistička značajnost u optimizaciji pretvorbe? Razina statističke značajnosti
Statistička pouzdanost ključna je u FCC-ovoj praksi izračuna. Prethodno je navedeno da se iz iste populacije može odabrati više uzoraka:
Ako su pravilno odabrani, tada se njihovi prosječni pokazatelji i pokazatelji opće populacije neznatno razlikuju jedni od drugih u veličini pogreške reprezentativnosti, uzimajući u obzir prihvaćenu pouzdanost;
Ako su odabrani iz različitih populacija, razlika među njima je značajna. Statistika se temelji na usporedbi uzoraka;
Ako se neznatno, nenačelno, beznačajno razlikuju, tj. zapravo pripadaju istoj općoj populaciji, razlika među njima naziva se statistički nepouzdanom.
Statistički pouzdano Razlika u uzorku je uzorak koji se bitno i suštinski razlikuje, odnosno pripada različitim općim populacijama.
FCC procjena statistička značajnost razlike u uzorku znači rješavanje mnogih praktičnih problema. Primjerice, uvođenje novih nastavnih metoda, programa, skupova vježbi, testova, kontrolnih vježbi povezano je s njihovim eksperimentalnim ispitivanjem, koje treba pokazati da se ispitna skupina bitno razlikuje od kontrolne. Stoga se koriste posebne statističke metode, koje se nazivaju kriteriji statističke značajnosti, za otkrivanje prisutnosti ili odsutnosti statistički značajne razlike između uzoraka.
Svi kriteriji su podijeljeni u dvije skupine: parametarske i neparametarske. Parametarski kriteriji zahtijevaju postojanje normalnog zakona raspodjele, tj. To znači obvezno određivanje glavnih pokazatelja normalnog zakona - aritmetičke sredine i standardne devijacije s. Parametarski kriteriji su najtočniji i najtočniji. Neparametrijski testovi temelje se na rang (ordinalnim) razlikama između elemenata uzorka.
Evo glavnih kriterija za statističku značajnost koji se koriste u FCC praksi: Studentov test i Fisherov test.
Studentov t test nazvana po engleskom znanstveniku K. Gossetu (Student - pseudonim), koji je otkrio ovu metodu. Studentov test je parametarski i koristi se za usporedbu apsolutnih vrijednosti uzoraka. Uzorci mogu varirati u veličini.
Studentov t test definiran je ovako.
1. Pronađite Studentov t test pomoću sljedeće formule:
gdje su aritmetičke sredine uspoređivanih uzoraka; t 1, t 2 - pogreške reprezentativnosti utvrđene na temelju pokazatelja uspoređivanih uzoraka.
2. Praksa u FCC-u je pokazala da je za sportski rad dovoljno prihvatiti pouzdanost računa P = 0,95.
Za pouzdanost brojanja: P = 0,95 (a = 0,05), s brojem stupnjeva slobode
k = n 1 + n 2 - 2 pomoću tablice u Dodatku 4 nalazimo vrijednost granične vrijednosti kriterija ( t gr).
3. Na temelju svojstava zakona normalne distribucije, Studentov kriterij uspoređuje t i t gr.
Izvodimo zaključke:
ako je t t gr, tada je razlika između uspoređivanih uzoraka statistički značajna;
ako je t t gr, tada je razlika statistički beznačajna.
Za istraživače u području FCS-a, procjena statističke značajnosti prvi je korak u rješavanju specifičnog problema: jesu li uzorci koji se uspoređuju fundamentalno ili nefundamentalno različiti jedni od drugih. Sljedeći korak je evaluacija te razlike s pedagoškog stajališta, što je određeno uvjetima zadatka.
Razmotrimo primjenu Studentovog testa na konkretan primjer.
Primjer 2.14. Grupi od 18 ispitanika procijenjen je broj otkucaja srca (bpm) prije x i i poslije y i zagrijati se.
Procijenite učinkovitost zagrijavanja na temelju otkucaja srca. Početni podaci i izračuni prikazani su u tablici. 2.30 i 2.31.
Tablica 2.30
Obrada indikatora otkucaja srca prije zagrijavanja
Pogreške za obje skupine su se podudarale, budući da su veličine uzorka jednake (istu skupinu proučava različitim uvjetima), a standardne devijacije bile su s x = s y = 3 otkucaja/min. Prijeđimo na definiranje Studentovog testa:
Postavljamo pouzdanost računa: P = 0,95.
Broj stupnjeva slobode k 1 = n 1 + n 2 - 2 = 18 + 18-2 = 34. Iz tablice u prilogu 4 nalazimo t gr= 2,02.
Statističko zaključivanje. Kako je t = 11,62, a granica t gr = 2,02, onda je 11,62 > 2,02, tj. t > t gr, stoga je razlika između uzoraka statistički značajna.
Pedagoški zaključak. Utvrđeno je da je u pogledu otkucaja srca razlika između stanja grupe prije i poslije zagrijavanja statistički značajna, tj. značajan, temeljan. Dakle, na temelju pokazatelja otkucaja srca možemo zaključiti da je zagrijavanje učinkovito.
Fisherov kriterij je parametarski. Koristi se kada se uspoređuju stope disperzije uzorka. To obično znači usporedbu u smislu stabilnosti sportske izvedbe ili stabilnosti funkcionalnih i tehničkih pokazatelja u praksi fizička kultura i sport. Uzorci mogu biti različitih veličina.
Fisherov kriterij je definiran u sljedećem nizu.
1. Pronađite Fisherov kriterij F pomoću formule
gdje su varijance uspoređivanih uzoraka.
Uvjeti Fisherova kriterija nalažu da se u brojniku formule F postoji velika disperzija, tj. broj F je uvijek veći od jedan.
Postavljamo pouzdanost brojanja: P = 0,95 - i određujemo broj stupnjeva slobode za oba uzorka: k 1 = n 1 - 1, k 2 = n 2 - 1.
Pomoću tablice u Dodatku 4 nalazimo graničnu vrijednost kriterija F gr.
Usporedba F i F kriterija gr omogućuje nam da formuliramo zaključke:
ako je F > F gr, tada je razlika između uzoraka statistički značajna;
ako F< F гр, то различие между выборками статически недостоверно.
Navedimo konkretan primjer.
Primjer 2.15. Analizirajmo dvije skupine rukometaša: x i (n 1= 16 osoba) i y i (p 2 = 18 osoba). Ove skupine sportaša proučavane su za vrijeme (s) odskoka prilikom bacanja lopte u gol.
Jesu li indikatori odbijanja iste vrste?
Početni podaci i osnovni izračuni prikazani su u tablici. 2.32 i 2.33.
Tablica 2.32
Obrada pokazatelja odbijanja prve skupine rukometaša
Definirajmo Fisherov kriterij:
Prema podacima prikazanim u tablici u Dodatku 6, nalazimo Fgr: Fgr = 2,4
Obratimo pozornost na činjenicu da su u tablici Dodatka 6 navedeni brojevi stupnjeva slobode i veće i manje disperzije pri približavanju veliki brojevi postaje grublji. Dakle, broj stupnjeva slobode veće disperzije slijedi ovim redom: 8, 9, 10, 11, 12, 14, 16, 20, 24 itd., a manje - 28, 29, 30, 40. , 50, itd. d.
To se objašnjava činjenicom da se s povećanjem veličine uzorka razlike u F-testu smanjuju i moguće je koristiti tablične vrijednosti koje su bliske izvornim podacima. Dakle, u primjeru 2.15 =17 nema i možemo uzeti njemu najbližu vrijednost k = 16, iz čega dobivamo Fgr = 2.4.
Statističko zaključivanje. Budući da je Fisherov test F= 2,5 > F= 2,4, uzorci se statistički značajno razlikuju.
Pedagoški zaključak. Vrijednosti vremena uzleta (s) pri ubacivanju lopte u gol za rukometaše obje skupine značajno se razlikuju. Ove skupine treba smatrati različitima.
Daljnja istraživanja trebala bi otkriti razlog ove razlike.
Primjer 2.20.(na statističku pouzdanost uzorka ). Jesu li se kvalifikacije nogometaša popravile ako je vrijeme(a) od davanja znaka do udarca lopte na početku treninga bilo x i , a na kraju y i .
Početni podaci i osnovni proračuni dati su u tablici. 2.40 i 2.41.
Tablica 2.40
Indikatori vremena obrade od davanja signala do udarca lopte na početku treninga
Odredimo razliku između skupina indikatora koristeći Studentov kriterij:
![]()
Uz pouzdanost P = 0,95 i stupnjeve slobode k = n 1 + n 2 - 2 = 22 + 22 - 2 = 42, pomoću tablice u Dodatku 4 nalazimo t gr= 2,02. Budući da je t = 8,3 > t gr= 2,02 - razlika je statistički značajna.
Odredimo razliku između skupina pokazatelja koristeći Fisherov kriterij:
| |
Prema tablici u Prilogu 2, uz pouzdanost P = 0,95 i stupnjeve slobode k = 22-1 = 21, vrijednost F gr = 21. Budući da je F = 1,53< F гр = = 2,1, различие в рассеивании исходных данных статистически недостоверно.
Statističko zaključivanje. Prema aritmetičkom prosjeku, razlika između skupina pokazatelja je statistički značajna. U smislu disperzije (raspršenosti), razlika između skupina pokazatelja je statistički nepouzdana.
Pedagoški zaključak. Kvalifikacije nogometaša znatno su poboljšane, ali treba obratiti pozornost na stabilnost njegovog iskaza.
Priprema za rad
Prije izvođenja ovog laboratorijskog rada iz discipline “Sportsko mjeriteljstvo” svim studentima grupa za učenje potrebno je formirati radne timove od 3-4 učenika u svakom, da zajednički izvrše radni zadatak svih laboratorijskih radova.
U pripremi za rad upoznajte se s relevantnim dijelovima preporučene literature (vidi odjeljak 6 ovih smjernica) i bilješkama s predavanja. Proučiti 1. i 2. dio ovog laboratorijskog rada, kao i radni zadatak (4. dio).
Pripremite obrazac za izvješće na standardni listovi papir za pisanje A4 formata i u njega dodati materijale potrebne za rad.
Izvješće mora sadržavati :
Naslovnica s naznakom odjela (UC i TR), studijske grupe, prezimena, imena, patronima studenta, broja i naziva laboratorijskog rada, datuma njegovog završetka te prezimena, akademskog stupnja, znanstvenog zvanja i radnog mjesta učitelj prihvaća rad;
Cilj rada;
Formule s numeričkim vrijednostima koje objašnjavaju srednje i konačne rezultate izračuna;
Tablice izmjerenih i izračunatih vrijednosti;
Grafički materijal potreban zadatkom;
Kratki zaključci o rezultatima svake etape radnog zadatka i općenito o obavljenom radu.
Svi grafikoni i tablice pažljivo su nacrtani pomoću alata za crtanje. Konvencionalni grafički i slovni simboli moraju biti u skladu s GOST-ovima. Dopuštena je izrada izvješća pomoću računalne tehnologije.
Radni zadatak
Prije provođenja svih mjerenja, svaki član tima mora proučiti pravila korištenja sportska igra Pikado dat u Prilogu 7. koji je potreban za provođenje sljedećih faza istraživanja.
I. faza istraživanja“Proučavanje rezultata pogađanja sportske mete Pikado igre svaki član tima za usklađenost s normalnim zakonom raspodjele prema kriteriju χ 2 Pearson i kriterij tri sigme"
1. izmjeriti (testirati) svoju (osobnu) brzinu i koordinaciju radnji, bacanjem strelice 30-40 puta u kružnu metu u sportskoj igri Pikado.
2. Rezultati mjerenja (ispitivanja) x i(nosi naočale) složiti u formu varijacijske serije i unesite u tablicu 4.1 (kolone , učinite sve potrebne kalkulacije, popunite potrebne tablice i izvucite odgovarajuće zaključke o usklađenosti rezultirajuće empirijske distribucije s normalnim zakonom distribucije, analogno sličnim izračunima, tablicama i zaključcima primjera 2.12, danim u odjeljku 2 ovih smjernica na stranicama 7 -10.
Tablica 4.1
Podudarnost brzine i koordinacije djelovanja subjekata s normalnim zakonom raspodjele
| Ne. | zaobljena | |||||||||
| … | ||||||||||
| … | ||||||||||
| Ukupno |
II – faza istraživanja
“Procjena prosječnih pokazatelja opće populacije pogodaka u metu sportske igre Pikado svih studenata studijske grupe na temelju rezultata mjerenja članova jedne ekipe”
Procijeniti prosječne pokazatelje brzine i koordinacije djelovanja svih učenika u studijskoj skupini (prema popisu učne skupine u razrednom časopisu) na temelju dobivenih rezultata pogađanja mete sportske igre Pikado svih članova ekipe. u prvoj fazi istraživanja ovog laboratorijskog rada.
1. Dokumentirati rezultate mjerenja brzine i koordinacije djelovanja prilikom bacanja pikada u kružnu metu u sportskoj igri Pikado svih članova svoje ekipe (2 - 4 osobe), koji predstavljaju uzorak rezultata mjerenja iz opće populacije (rezultati mjerenja svih studenata studijske grupe - npr. 15 osoba), unoseći ih u drugi i treći stupac Tablica 4.2.
Tablica 4.2
Obrada pokazatelja brzine i koordinacije radnji
pripadnici brigade
| Ne. | ||||||
| … | ||||||
| … | ||||||
| Ukupno |
U tablici 4.2 pod treba razumjeti , usklađeni prosječni rezultat (vidi rezultate izračuna u tablici 4.1) članovi vašeg tima ( , dobivenih u prvoj fazi istraživanja. Treba napomenuti da, obično, Tablica 4.2 sadrži izračunatu prosječnu vrijednost rezultata mjerenja jednog člana tima u prvoj fazi istraživanja. , jer je vjerojatnost da će se rezultati mjerenja različitih članova tima podudarati vrlo mala. Zatim, u pravilu vrijednosti u koloni Tablica 4.2 za svaki red - jednako 1, A u retku “Ukupno " stupci " ", je napisano broj članova vašeg tima.
2. Izvršite sve potrebne izračune za popunjavanje tablice 4.2, kao i druge izračune i zaključke slične izračunima i zaključcima iz primjera 2.13 danim u 2. odjeljku ovog metodološki razvoj na stranicama 13-14. To treba imati na umu pri izračunavanju pogreške reprezentativnosti "m" potrebno je koristiti formulu 2.4 danu na stranici 13 ovog metodološkog razvoja, budući da je uzorak mali (n, a broj elemenata opće populacije N je poznat, a jednak je broju studenata u studijskoj grupi, prema popisu časopisa studijske grupe.
III – faza istraživanja
Procjena učinkovitosti zagrijavanja prema pokazatelju "Brzina i koordinacija akcija" od strane svakog člana tima pomoću Studentovog t-testa
Za procjenu učinkovitosti zagrijavanja za bacanje strelica u metu sportske igre "Pikado", izvedene u prvoj fazi istraživanja ovog laboratorijskog rada, svaki član tima prema pokazatelju "Brzina i koordinacija radnji", koristeći Studentov kriterij - parametarski kriterij za statističku pouzdanost empirijskog zakona raspodjele prema normalnom zakonu raspodjele .
2. odstupanja i RMS , rezultati mjerenja pokazatelja "Brzina i koordinacija radnji" na temelju rezultata zagrijavanja, dano u tablici 4.3, (vidi slične izračune dane odmah nakon tablice 2.30 primjera 2.14 na stranici 16 ovog metodološkog razvoja).
3. Svaki član radnog tima izmjeriti (testirati) svoju (osobnu) brzinu i koordinaciju radnji nakon zagrijavanja,
5. Izvršite prosječne izračune odstupanja i RMS ,rezultati mjerenja indikatora "Brzina i koordinacija radnji" nakon zagrijavanja, dano u tablici 4.4, zapišite ukupne rezultate mjerenja na temelju rezultata zagrijavanja (vidi slične izračune dane odmah nakon tablice 2.31 primjera 2.14 na stranici 17 ovog metodološkog razvoja).
6. Izvedite sve potrebne izračune i zaključke slične izračunima i zaključcima iz primjera 2.14 danim u 2. odjeljku ovog metodološkog razvoja na stranicama 16-17. To treba imati na umu pri izračunavanju pogreške reprezentativnosti "m" potrebno je koristiti formulu 2.1 danu na stranici 12 ovog metodološkog razvoja, budući da je uzorak n, a broj elemenata u populaciji N ( nije poznat.
IV – faza istraživanja
Procjena ujednačenosti (stabilnosti) pokazatelja „Brzina i koordinacija djelovanja” dva člana tima korištenjem Fisherovog kriterija
Procijeniti ujednačenost (stabilnost) pokazatelja „Brzina i koordinacija djelovanja” dvaju članova tima pomoću Fisherovog kriterija, na temelju rezultata mjerenja dobivenih u trećoj fazi istraživanja u ovom laboratorijskom radu.
Da biste to učinili morate učiniti sljedeće.
Korištenjem podataka iz tablica 4.3 i 4.4, rezultata izračuna varijanci iz ovih tablica dobivenih u trećoj fazi istraživanja, kao i metodologije izračuna i primjene Fisherovog kriterija za ocjenu ujednačenosti (stabilnosti) sportskih pokazatelja, danih u primjer 2.15 na stranicama 18-19 ovog metodološkog razvoja, izvući odgovarajuće statističke i pedagoške zaključke.
V – faza istraživanja
Procjena skupine pokazatelja “Brzina i koordinacija akcija” jednog člana tima prije i poslije zagrijavanja
Razina značajnosti - ovo je vjerojatnost da smo razlike smatrali značajnima, ali one su zapravo slučajne.
Kada naznačimo da su razlike značajne na razini značajnosti od 5%, ili kada R< 0,05 , onda mislimo da je vjerojatnost da su nepouzdani 0,05.
Kada naznačimo da su razlike značajne na razini značajnosti od 1%, ili kada R< 0,01 , onda mislimo da je vjerojatnost da su nepouzdani 0,01.
Ako sve ovo prevedemo na formaliziraniji jezik, tada je razina značajnosti vjerojatnost odbacivanja nulte hipoteze, dok je istinita.
pogreška,koja se sastoji odonajšto miodbijenaNulta hipotezaiako je točna, naziva se pogreška tipa 1.(Pogledajte tablicu 1)
Stol 1. Nulte i alternativne hipoteze i mogući uvjeti ispitivanja.
Vjerojatnost takve pogreške obično se označava kao α. U biti, morali bismo u zagradi označiti ne str < 0,05 ili str < 0,01 i α < 0,05 ili α < 0,01.
Ako je vjerojatnost greške α , tada je vjerojatnost ispravne odluke: 1-α. Što je α manji, veća je vjerojatnost ispravne odluke.
Povijesno gledano, u psihologiji je prihvaćeno da najniža razina statistička značajnost je razina od 5% (p≤0,05): dovoljna je razina od 1% (p≤0,01), a najveća je razina od 0,1% (p≤0,001), stoga je u tablicama kritičnih vrijednosti obično dane su vrijednosti kriterija koji odgovaraju razinama statističke značajnosti p≤0,05 i p≤0,01, ponekad - p≤0,001. Za neke kriterije tablice pokazuju precizna razina značaj njihovih različitih empirijskih značenja. Na primjer, za φ*=1,56 p=O,06.
Međutim, dok razina statističke značajnosti ne dosegne p=0,05, nemamo pravo odbaciti nultu hipotezu. Pridržavat ćemo se sljedećeg pravila za odbacivanje hipoteze o nepostojanju razlika (Ho) i prihvaćanje hipoteze o statističkoj značajnosti razlika (H 1).
Pravilo za odbijanje Ho i prihvaćanje h1
Ako je empirijska vrijednost testa jednaka ili veća od kritične vrijednosti koja odgovara p≤0,05, tada se H 0 odbacuje, ali još ne možemo definitivno prihvatiti H 1 .
Ako je empirijska vrijednost kriterija jednaka kritičnoj vrijednosti koja odgovara p≤0,01 ili je premašuje, tada se H 0 odbacuje, a H 1 prihvaća.
Iznimke : G znak test, Wilcoxonov T test i Mann-Whitney U test. Za njih se uspostavljaju inverzni odnosi.

Riža. 4. Primjer "osi značajnosti" za Rosenbaumov Q kriterij.
Kritične vrijednosti kriterija označene su kao Q o, o5 i Q 0,01, empirijska vrijednost kriterija kao Q em. Zatvoren je u elipsu.
Desno od kritične vrijednosti Q 0,01 proteže se "zona značajnosti" - to uključuje empirijske vrijednosti koje prelaze Q 0,01 i stoga su sigurno značajne.
Lijevo od kritične vrijednosti Q 0,05 proteže se "zona beznačajnosti" - to uključuje empirijske Q vrijednosti koje su ispod Q 0,05 i stoga su sigurno beznačajne.
Vidimo to Q 0,05 =6; Q 0,01 =9; Q em. =8;
Empirijska vrijednost kriterija pada u područje između Q 0,05 i Q 0,01. To je zona “nesigurnosti”: već sada možemo odbaciti hipotezu o nepouzdanosti razlika (H 0), ali još ne možemo prihvatiti hipotezu o njihovoj pouzdanosti (H 1).
U praksi, međutim, istraživač može smatrati pouzdanima one razlike koje ne spadaju u zonu beznačajnosti, proglašavajući ih pouzdanima na p. < 0,05, ili navođenjem točne razine značajnosti dobivene vrijednosti empirijskog kriterija, npr.: p=0,02. Koristeći standardne tablice, koje se nalaze u svim udžbenicima matematičkih metoda, to se može učiniti u odnosu na Kruskal-Wallis H kriterij, χ 2 r Friedman, Pageov L, Fisherov φ* .
Razina statističke značajnosti, odnosno kritične testne vrijednosti, određuje se različito kada se testiraju usmjerene i neusmjerene statističke hipoteze.
Uz usmjerenu statističku hipotezu koristi se jednostrani test, uz neusmjerenu hipotezu koristi se dvostrani test. Dvosmjerni test je stroži jer testira razlike u oba smjera, pa stoga empirijska vrijednost testa koja je prethodno odgovarala razini značajnosti p < 0,05, sada odgovara samo p razini < 0,10.
Nećemo morati svaki put sami odlučivati koristi li se jednostranim ili dvostranim kriterijem. Tablice kritičnih vrijednosti kriterija odabrane su na način da usmjerene hipoteze odgovaraju jednostranom kriteriju, a neusmjerene hipoteze odgovaraju dvostranom kriteriju, a zadane vrijednosti zadovoljavaju zahtjeve da primijeniti na svaku od njih. Istraživač samo treba osigurati da se njegove hipoteze po značenju i obliku podudaraju s hipotezama predloženim u opisu svakog od kriterija.
Kada se opravdava statističko zaključivanje, mora se postaviti pitanje: gdje je granica između prihvaćanja i odbijanja nulte hipoteze? Zbog prisutnosti slučajnih utjecaja u eksperimentu, ova se granica ne može povući apsolutno točno. Temelji se na konceptu razina značaja. Razina značaja naziva se vjerojatnost lažnog odbacivanja nulte hipoteze. Ili, drugim riječima, razina značajnosti - Ovo je vjerojatnost pogreške tipa I pri donošenju odluke. Za označavanje te vjerojatnosti, u pravilu, koriste ili grčko slovo α ili latinično slovo R. U nastavku ćemo koristiti slovo R.
Povijesno gledano, u primijenjenim znanostima koje se koriste statistikom, a posebice u psihologiji, najnižom razinom statističke značajnosti smatra se razina p = 0,05; dovoljna - razina R= 0,01 i najviša razina p = 0,001. Stoga se u statističkim tablicama koje su date u prilogu udžbenika statistike obično daju tablične vrijednosti za razine p = 0,05, p = 0,01 i R= 0,001. Ponekad se daju tablične vrijednosti za razine R - 0,025 i p = 0,005.
Vrijednosti od 0,05, 0,01 i 0,001 su takozvane standardne razine statističke značajnosti. Pri statističkoj analizi eksperimentalnih podataka, psiholog, ovisno o ciljevima i hipotezama istraživanja, mora odabrati potrebnu razinu značajnosti. Kao što vidimo, ovdje je najveća vrijednost, odnosno donja granica razine statističke značajnosti jednaka 0,05 – to znači da je dopušteno pet pogrešaka u uzorku od stotinu elemenata (slučajeva, subjekata) ili jedna greška od dvadeset. elementi (slučajevi, subjekti). Vjeruje se da ne možemo pogriješiti ni šest, ni sedam, ni više puta od stotinu. Cijena takvih pogrešaka bit će previsoka.
Imajte na umu da moderni statistički paketi na računalima ne koriste standardne razine značajnosti, već razine izračunate izravno u procesu rada s odgovarajućom statističkom metodom. Ove razine, označene slovom R, može imati različit numerički izraz u rasponu od 0 do 1, na primjer, p = 0,7, R= 0,23 ili R= 0,012. Jasno je da su u prva dva slučaja dobivene razine značajnosti previsoke i nemoguće je reći da je rezultat značajan. Istovremeno, u potonjem slučaju rezultati su značajni na razini od 12 tisućinki. Ovo je pouzdana razina.
Pravilo za prihvaćanje statističkog zaključka je sljedeće: na temelju dobivenih eksperimentalnih podataka psiholog izračunava tzv. empirijsku statistiku, odnosno empirijsku vrijednost, koristeći statističku metodu koju je odabrao. Prikladno je ovu količinu označiti kao H em . Zatim empirijska statistika H em uspoređuje se s dvije kritične vrijednosti koje odgovaraju razinama značajnosti od 5% i 1% za odabranu statističku metodu i koje su označene kao H kr . Količine H kr nalaze se za danu statističku metodu korištenjem odgovarajućih tablica danih u dodatku bilo kojeg statističkog udžbenika. Te su količine u pravilu uvijek različite i u nastavku se, zbog praktičnosti, mogu nazvati H kr1 I H kr2 . Kritične vrijednosti pronađene iz tablica H kr1 I H kr2 Pogodno je to prikazati u sljedećem standardnom notnom obliku:
Naglašavamo, međutim, da smo koristili notaciju H em I H kr kao skraćenica od riječi "broj". Sve statističke metode usvojile su vlastite simboličke oznake za sve ove veličine: i empirijsku vrijednost izračunatu odgovarajućom statističkom metodom i kritičnu vrijednost dobivenu iz odgovarajućih tablica. Na primjer, pri izračunavanju Spearmanova koeficijenta korelacije ranga pomoću tablice kritičnih vrijednosti ovog koeficijenta, pronađene su sljedeće kritične vrijednosti koje su za ovu metodu označene grčkim slovom ρ ("rho"). Dakle za p = 0,05 vrijednost pronađena iz tablice ρ kr 1 = 0,61 i za p = 0,01 magnitude ρ kr 2 = 0,76.
U standardnom obliku notacije usvojenom u sljedećoj prezentaciji, to izgleda ovako:

Sada moramo usporediti našu empirijsku vrijednost s dvije kritične vrijednosti koje se nalaze u tablicama. Najbolji način da to učinite je da postavite sva tri broja na ono što se naziva "os značajnosti". “Os značajnosti” je ravna linija, na čijem je lijevom kraju 0, iako ona, u pravilu, nije označena na samoj ovoj pravoj liniji, a s lijeva na desno dolazi do povećanja niza brojeva. Zapravo, ovo je uobičajena školska apscisna os OH Kartezijev koordinatni sustav. Međutim, osobitost ove osi je da ima tri dijela, "zone". Jedna ekstremna zona naziva se zona beznačajnosti, druga ekstremna zona naziva se zona značajnosti, a srednja zona naziva se zona neizvjesnosti. Granice sve tri zone su H kr1 Za p = 0,05 i H kr2 Za p = 0,01, kao što je prikazano na slici.
Ovisno o pravilu odlučivanja (pravilu zaključivanja) propisanom u ovoj statističkoj metodi, moguće su dvije opcije.
Prva opcija: alternativna hipoteza je prihvaćena ako H em ≥H kr .

Ili druga opcija: alternativna hipoteza se prihvaća ako H em ≤H kr .

Prebrojano H em prema nekoj statističkoj metodi mora nužno spadati u jednu od tri zone.
Ako empirijska vrijednost spada u zonu beznačajnosti, tada se prihvaća hipoteza H 0 o nepostojanju razlika.
Ako H em spada u zonu značajnosti, prihvaća se alternativna hipoteza H 1 O prisutnost razlika, a hipoteza H 0 je odbačena.
Ako H em pada u zonu neizvjesnosti, istraživač se suočava s dilemom. Dakle, ovisno o važnosti problema koji rješava, dobivenu statističku procjenu može smatrati pouzdanom na razini od 5%, te time prihvatiti hipotezu H 1, odbacujući hipotezu H 0 , ili - nepouzdan na razini od 1%, čime se prihvaća hipoteza H 0. Naglašavamo, međutim, da je upravo to slučaj kada psiholog može pogriješiti prve ili druge vrste. Kao što je gore navedeno, u ovim okolnostima najbolje je povećati veličinu uzorka.
Naglasimo i to da vrijednost H em može točno odgovarati bilo kojem H kr1 ili H kr2 . U prvom slučaju možemo pretpostaviti da je procjena pouzdana na točno 5% razini i prihvatiti hipotezu H 1, ili obrnuto, prihvatiti hipotezu H 0. U drugom slučaju, u pravilu se prihvaća alternativna hipoteza H 1 o postojanju razlika, a hipoteza H 0 se odbacuje.
Razina značajnosti u statistici važan je pokazatelj koji odražava stupanj povjerenja u točnost i istinitost dobivenih (predviđenih) podataka. Koncept se široko koristi u raznim područjima: od dirigiranja sociološka istraživanja, prije statističkog testiranja znanstvenih hipoteza.
Definicija
Razina statističke značajnosti (ili statistički značajan rezultat) pokazuje koliko je vjerojatno da se pokazatelji koji se proučavaju pojavljuju slučajno. Ukupna statistička značajnost neke pojave izražava se koeficijentom p-vrijednosti (p-razina). U svakom pokusu ili promatranju postoji mogućnost da su dobiveni podaci rezultat pogrešaka uzorkovanja. To posebno vrijedi za sociologiju.
Odnosno, statistički značajna vrijednost je ona čija je vjerojatnost slučajnog pojavljivanja izrazito mala ili teži ekstremu. Ekstrem u ovom kontekstu je stupanj do kojeg statistika odstupa od nulte hipoteze (hipoteze čija se dosljednost testira s dobivenim uzorkom podataka). U znanstvenoj praksi razina značajnosti odabire se prije prikupljanja podataka i u pravilu je njezin koeficijent 0,05 (5%). Za sustave u kojima su precizne vrijednosti izuzetno važne, ova brojka može biti 0,01 (1%) ili manje.

Pozadina
Koncept razine značajnosti uveo je britanski statističar i genetičar Ronald Fisher 1925. godine, kada je razvijao tehniku za testiranje statističkih hipoteza. Pri analizi bilo kojeg procesa postoji određena vjerojatnost određenih pojava. Poteškoće nastaju pri radu s malim (ili neočitim) postocima vjerojatnosti koji potpadaju pod koncept "pogreške mjerenja".
U radu sa statističkim podacima koji nisu dovoljno specifični da bi ih mogli testirati, znanstvenici se suočavaju s problemom nulte hipoteze koja “onemogućuje” operiranje s malim količinama. Fisher je za takve sustave predložio određivanje vjerojatnosti događaja na 5% (0,05) kao pogodan rez uzorkovanja, dopuštajući odbacivanje nulte hipoteze u izračunima.

Uvođenje fiksnih tečajeva
Godine 1933 znanstvenici Jerzy Neyman i Egon Pearson u svojim su radovima preporučili postavljanje određene razine značajnosti unaprijed (prije prikupljanja podataka). Primjeri korištenja ovih pravila jasno su vidljivi tijekom izbora. Recimo da postoje dva kandidata, od kojih je jedan vrlo popularan, a drugi malo poznat. Očito je da će na izborima pobijediti prvi kandidat, a šanse drugoga teže nuli. Trude se – ali nisu jednaki: uvijek postoji mogućnost više sile, senzacionalnih informacija, neočekivanih odluka koje mogu promijeniti predviđene rezultate izbora.
Neyman i Pearson su se složili da je Fisherova razina značajnosti od 0,05 (označena s α) najprikladnija. Međutim, sam Fischer 1956. protivio se fiksiranju te vrijednosti. Vjerovao je da se razina α treba postaviti prema specifičnim okolnostima. Na primjer, u fizici čestica to je 0,01.

vrijednost p-razine
Pojam p-vrijednost prvi je upotrijebio Brownlee 1960. P-razina (p-vrijednost) je pokazatelj koji je u obrnuti odnos o istinitosti rezultata. Najviši koeficijent p-vrijednosti odgovara najnižoj razini pouzdanosti u uzorkovani odnos između varijabli.
Ova vrijednost odražava vjerojatnost pogrešaka povezanih s tumačenjem rezultata. Pretpostavimo da je p-razina = 0,05 (1/20). Pokazuje vjerojatnost od pet posto da je odnos između varijabli pronađenih u uzorku samo slučajna značajka uzorka. Odnosno, ako te ovisnosti nema, onda se ponavljanjem sličnih eksperimenata, u prosjeku, u svakom dvadesetom istraživanju, može očekivati ista ili veća ovisnost između varijabli. P-razina se često smatra "marginom" za stopu pogreške.
Usput, p-vrijednost možda neće odražavati stvarna ovisnost između varijabli, ali pokazuje samo određenu prosječnu vrijednost unutar pretpostavki. Konkretno, konačna analiza podataka također će ovisiti o odabranim vrijednostima ovog koeficijenta. Na p-razini = 0,05 bit će nekih rezultata, a na koeficijentu jednakom 0,01 bit će drugačijih rezultata.

Testiranje statističkih hipoteza
Razina statističke značajnosti posebno je važna kod testiranja hipoteza. Na primjer, kada se izračunava dvostrani test, područje odbijanja jednako se dijeli na oba kraja distribucije uzorkovanja (u odnosu na nultu koordinatu) i izračunava se istinitost dobivenih podataka.
Pretpostavimo da se prilikom praćenja određenog procesa (fenomena) pokaže da novi statistički podaci pokazuju male promjene u odnosu na prethodne vrijednosti. Istodobno, odstupanja u rezultatima su mala, nisu očita, ali važna za studiju. Specijalist je suočen s dilemom: događaju li se doista promjene ili su to pogreške uzorkovanja (netočnost mjerenja)?
U tom slučaju koriste ili odbacuju nultu hipotezu (sve pripisuju pogrešci ili promjenu u sustavu prepoznaju kao svršenu činjenicu). Proces rješavanja problema temelji se na omjeru ukupne statističke značajnosti (p-vrijednosti) i razine značajnosti (α). Ako je p-razina< α, значит, нулевую гипотезу отвергают. Чем меньше р-value, тем более значимой является тестовая статистика.
Korištene vrijednosti
Razina značajnosti ovisi o materijalu koji se analizira. U praksi se koriste sljedeće fiksne vrijednosti:
- α = 0,1 (ili 10%);
- α = 0,05 (ili 5%);
- α = 0,01 (ili 1%);
- α = 0,001 (ili 0,1%).
Što su točniji izračuni potrebni, to se niži koeficijent α koristi. Naravno, statističke prognoze u fizici, kemiji, farmaciji i genetici zahtijevaju veću točnost nego u političkim znanostima i sociologiji.

Pragovi značajnosti u određenim područjima
U područjima visoke preciznosti kao što su fizika čestica i proizvodna djelatnost, statistička značajnost često se izražava kao omjer standardne devijacije (označene sigma koeficijentom – σ) u odnosu na normalnu distribuciju vjerojatnosti (Gaussova distribucija). σ je statistički pokazatelj koji određuje disperziju vrijednosti određene veličine u odnosu na matematička očekivanja. Koristi se za iscrtavanje vjerojatnosti događaja.
Ovisno o području znanja, koeficijent σ jako varira. Na primjer, kada se predviđa postojanje Higgsovog bozona, parametar σ je jednak pet (σ = 5), što odgovara p-vrijednosti = 1/3,5 milijuna. U studijama genoma razina značajnosti može biti 5 × 10 -. 8, što nije neuobičajeno za ove krajeve.
Učinkovitost
Mora se uzeti u obzir da koeficijenti α i p-vrijednost nisu egzaktne karakteristike. Bez obzira na razinu značajnosti u statistici fenomena koji se proučava, to nije bezuvjetna osnova za prihvaćanje hipoteze. Na primjer, nego manje vrijednostiα, veća je vjerojatnost da je postavljena hipoteza značajna. Međutim, postoji rizik od pogreške, što smanjuje statističku snagu (značajnost) studije.
Istraživači koji se fokusiraju isključivo na statistiku značajne rezultate, može doći do pogrešnih zaključaka. U isto vrijeme, teško je još jednom provjeriti njihov rad, budući da primjenjuju pretpostavke (koje su zapravo α i p-vrijednosti). Stoga se uvijek preporuča, uz izračunavanje statističke značajnosti, odrediti još jedan pokazatelj - veličinu statističkog učinka. Veličina učinka je kvantitativna mjera snage učinka.
Statistika je odavno postala sastavni dio života. Ljudi ga susreću posvuda. Na temelju statistike donose se zaključci o tome gdje su i koje bolesti česte, što je više traženo u određenoj regiji ili među određenim segmentom stanovništva. Na tome se temelje čak i politički programi kandidata za vlast. Također se koriste trgovački lanci pri kupnji robe, a proizvođači se u svojim prijedlozima rukovode tim podacima.
Statistika igra važnu ulogu u životu društva i utječe na svakog pojedinog člana čak iu malim stvarima. Na primjer, ako do , većina ljudi preferira tamne boje u odjeći u određenom gradu ili regiji, bit će izuzetno teško pronaći jarko žuti baloner s cvjetnim printom u lokalnim prodajnim mjestima. Ali koje količine čine te podatke koji imaju takav utjecaj? Na primjer, što čini "statističku značajnost"? Što se točno podrazumijeva pod ovom definicijom?
Što je to?
Statistika kao znanost sastoji se od kombinacije različite veličine i pojmova. Jedan od njih je koncept "statističke značajnosti". Tako se nazivaju vrijednosti varijabli u kojima je vjerojatnost pojave drugih pokazatelja zanemariva.
Na primjer, 9 od 10 ljudi stavlja gumene cipele na noge tijekom jutarnje šetnje u branje gljiva u jesenskoj šumi nakon kišne noći. Vjerojatnost da će u nekom trenutku njih 8 nositi platnene mokasine je zanemariva. Dakle, u ovom konkretnom primjeru, broj 9 je vrijednost koja se naziva "statistička značajnost".
Sukladno tome, ako razvijemo sljedeći praktični primjer, trgovine cipelama kupuju gumene čizme u većim količinama pred kraj ljetne sezone nego u drugim razdobljima godine. Dakle, veličina statističke vrijednosti ima utjecaj na svakodnevni život.
Naravno, u složenim izračunima, na primjer, kada se predviđa širenje virusa, to se uzima u obzir veliki broj varijable. Ali sama bit definicije značajan pokazatelj statistički podaci - slični su, bez obzira na složenost izračuna i broj nekonstantnih veličina.
Kako se izračunava?
Koriste se pri izračunavanju vrijednosti pokazatelja "statističke značajnosti" jednadžbe. Odnosno, može se tvrditi da u ovom slučaju o svemu odlučuje matematika. Najviše jednostavna opcija proračun je lanac matematičkih operacija u kojima sljedeće parametre:
- dvije vrste rezultata dobivenih anketama ili proučavanjem objektivnih podataka, na primjer, iznosi za koje se kupuje, označeni a i b;
- pokazatelj za obje skupine - n;
- vrijednost udjela kombiniranog uzorka je p;
- koncept" standardna pogreška" - SE.
Sljedeći korak je određivanje općeg pokazatelja testa - t, njegova vrijednost se uspoređuje s brojem 1,96. 1,96 je prosječna vrijednost koja predstavlja raspon od 95% prema Studentovoj funkciji t-distribucije.
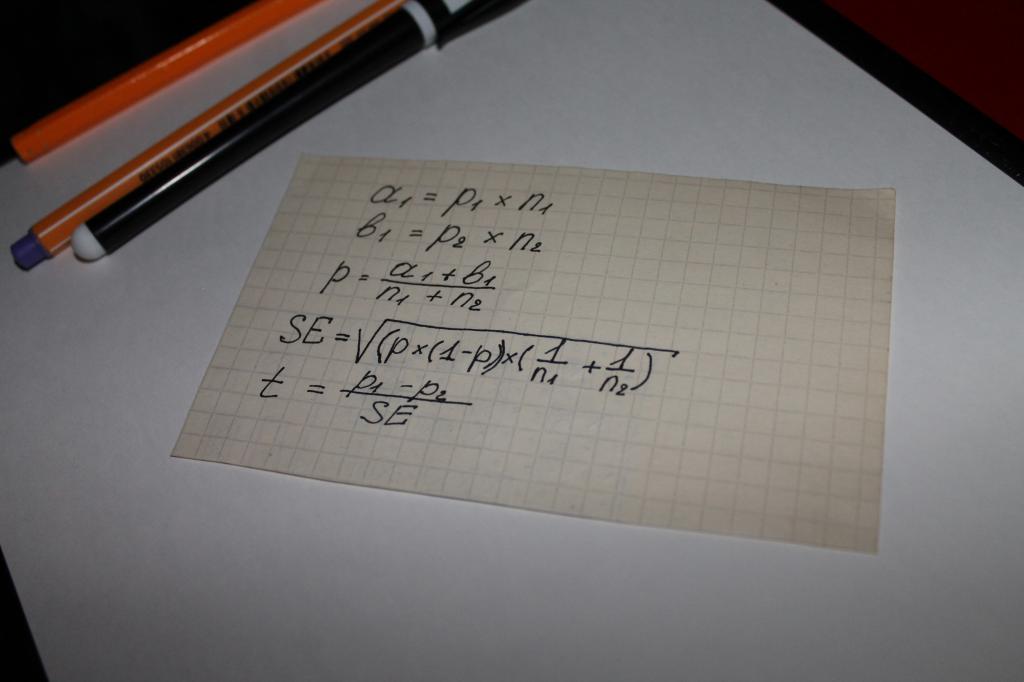
Često se postavlja pitanje koja je razlika između vrijednosti n i p. Ova se nijansa može lako razjasniti uz pomoć primjera. Recimo da izračunavamo statističku značajnost odanosti proizvodu ili robnoj marki za muškarce i žene.
U ovom slučaju, za slovne oznake pojavit će se sljedeće:
- n - broj ispitanika;
- p je broj ljudi zadovoljnih proizvodom.
Broj intervjuiranih žena u ovom slučaju bit će označen kao n1. Prema tome, ima n2 muškaraca. Brojevi "1" i "2" za simbol p imat će isto značenje.
Usporedba pokazatelja testa s prosječnim vrijednostima Studentovih računskih tablica postaje ono što se naziva "statistička značajnost".
Što se podrazumijeva pod provjerom?
Rezultati bilo kojeg matematičkog izračuna uvijek se mogu provjeriti; djeca se tome uče u osnovnoj školi. Logično je pretpostaviti da jednom statistički pokazatelji određuju se pomoću lanca izračuna, zatim se provjeravaju.
Međutim, testiranje statističke značajnosti ne odnosi se samo na matematiku. Statistika se bavi veliki iznos promjenjive veličine i razne vjerojatnosti, koje nisu uvijek izračunljive. Odnosno, ako se vratimo na primjer s gumenim cipelama naveden na početku članka, onda logičnu konstrukciju statističkih podataka na koje će se kupci robe za trgovine oslanjati može poremetiti suho i vruće vrijeme, netipično za jesen. Kao rezultat ovog fenomena, broj ljudi koji kupuju Gumene čizme, smanjit će se, i prodajna mjesta pretrpjet će gubitke. Matematička formula, naravno, ne može predvidjeti vremensku anomaliju. Ovaj trenutak se zove "pogreška".

Upravo se vjerojatnost takvih pogrešaka uzima u obzir pri provjeri razine izračunate značajnosti. Uzima u obzir oba izračunata pokazatelja i prihvaćene razine značaj, kao i količine koje se konvencionalno nazivaju hipotezama.
Koja je razina značajnosti?
Koncept "razine" uključen je u glavne kriterije za statističku značajnost. Koristi se u primijenjenoj i praktičnoj statistici. Ovo je vrsta vrijednosti koja uzima u obzir vjerojatnost mogućih odstupanja ili pogrešaka.
Razina se temelji na identificiranju razlika u gotovim uzorcima i omogućuje nam da utvrdimo njihovu važnost ili, obrnuto, slučajnost. Ovaj koncept nema samo digitalna značenja, već i njihova jedinstvena dekodiranja. Oni objašnjavaju kako treba razumjeti vrijednost, a sama razina se određuje usporedbom rezultata s prosječnim indeksom, što otkriva stupanj pouzdanosti razlika.

Dakle, pojam razine možemo zamisliti jednostavno - to je pokazatelj prihvatljive, vjerojatne pogreške ili pogreške u zaključcima izvučenim iz dobivenih statističkih podataka.
Koje se razine značajnosti koriste?
Statistička značajnost koeficijenata vjerojatnosti pogreške u praksi temelji se na tri osnovne razine.
Prvom razinom smatra se prag na kojem je vrijednost 5%. Odnosno, vjerojatnost pogreške ne prelazi razinu značajnosti od 5%. To znači da je povjerenje u besprijekornost i besprijekornost zaključaka donesenih na temelju podataka statističkih istraživanja 95%.
Druga razina je prag od 1%. Sukladno tome, ova brojka znači da se s 99% pouzdanosti može voditi podacima dobivenim tijekom statističkih izračuna.
Treća razina je 0,1%. S ovom vrijednošću vjerojatnost pogreške jednaka je djeliću postotka, odnosno pogreške su praktički eliminirane.
Što je hipoteza u statistici?
Pogreške kao koncept dijele se u dva smjera, a tiču se prihvaćanja ili odbijanja nulte hipoteze. Hipoteza je koncept iza kojeg se, prema definiciji, nalazi skup drugih podataka ili izjava. To jest, opis vjerojatnosne distribucije nečega što je povezano s predmetom statističkog računovodstva.

Hipoteze na jednostavni izračuni Postoje dva - nulti i alternativni. Razlika između njih je u tome što se nulta hipoteza temelji na ideji da ne postoje temeljne razlike između uzoraka uključenih u određivanje statističke značajnosti, a alternativna hipoteza je potpuno suprotna. To jest, alternativna hipoteza temelji se na prisutnosti značajne razlike u podacima uzorka.
Koje su greške?
Pogreške kao koncept u statistici izravno ovise o prihvaćanju jedne ili druge hipoteze kao istinite. Mogu se podijeliti u dva smjera ili vrste:
- prvi tip je zbog prihvaćanja nulte hipoteze, koja se pokaže netočnom;
- drugi je uzrokovan slijeđenjem alternative.

Prva vrsta pogreške naziva se lažno pozitivna i javlja se prilično često u svim područjima gdje se koriste statistički podaci. Prema tome, pogreška druge vrste naziva se lažno negativna.
Za što se koristi regresija u statistici?
Statistički značaj regresije je u tome što se može koristiti za određivanje koliko dobro model izračunat na temelju podataka odgovara stvarnosti razne ovisnosti; omogućuje vam da utvrdite dostatnost ili nedostatak faktora koje treba uzeti u obzir i donijeti zaključke.
Regresijska vrijednost određena je usporedbom rezultata s podacima navedenim u Fisherovim tablicama. Ili pomoću analize varijance. Regresijski pokazatelji važni su za složene statističke studije i proračune u kojima veliki broj varijable, slučajni podaci i vjerojatne promjene.